Inside AlloyDB: Google Cloud's Database for PostgreSQL Workloads
.png)
Introduction
Choosing the right cloud database can be overwhelming, especially with so many options promising performance and reliability. Google AlloyDB stands out by taking open-source PostgreSQL and enhancing it with Google’s powerful, cloud-native architecture. With features like lightning-fast transactions, built-in analytics, and automated management, AlloyDB lets you run demanding workloads and scale effortlessly—all while staying fully compatible with your existing Postgres apps and tools. In this post, we’ll explore what makes AlloyDB unique, how its architecture works, and how it compares to other managed PostgreSQL solutions.
What is Google AlloyDB?
Google AlloyDB is a fully managed, PostgreSQL-compatible cloud database service designed for demanding operational and hybrid workloads. In essence, AlloyDB takes open-source PostgreSQL and supercharges it with cloud-native enhancements, pairing a Google-built database engine with a multi-node, distributed architecture for enterprise-grade performance, reliability, and availability. It supports standard PostgreSQL connections and queries, so existing applications and tools work without changes.
AlloyDB was announced as Google’s answer to modernizing PostgreSQL on the cloud, combining the familiarity of Postgres with the scalability and automation of Google Cloud. Google touts impressive performance improvements: internal tests show AlloyDB is over 4× faster for transactional workloads and up to 100× faster for analytical queries compared to standard PostgreSQL. It also offers up to 2× better price-performance than self-managed Postgres, thanks to these optimizations. Importantly, it maintains 100% PostgreSQL compatibility, meaning it supports the same SQL syntax, drivers, and extensions, enabling easy migration of existing Postgres applications.
AlloyDB Architecture Under the Hood

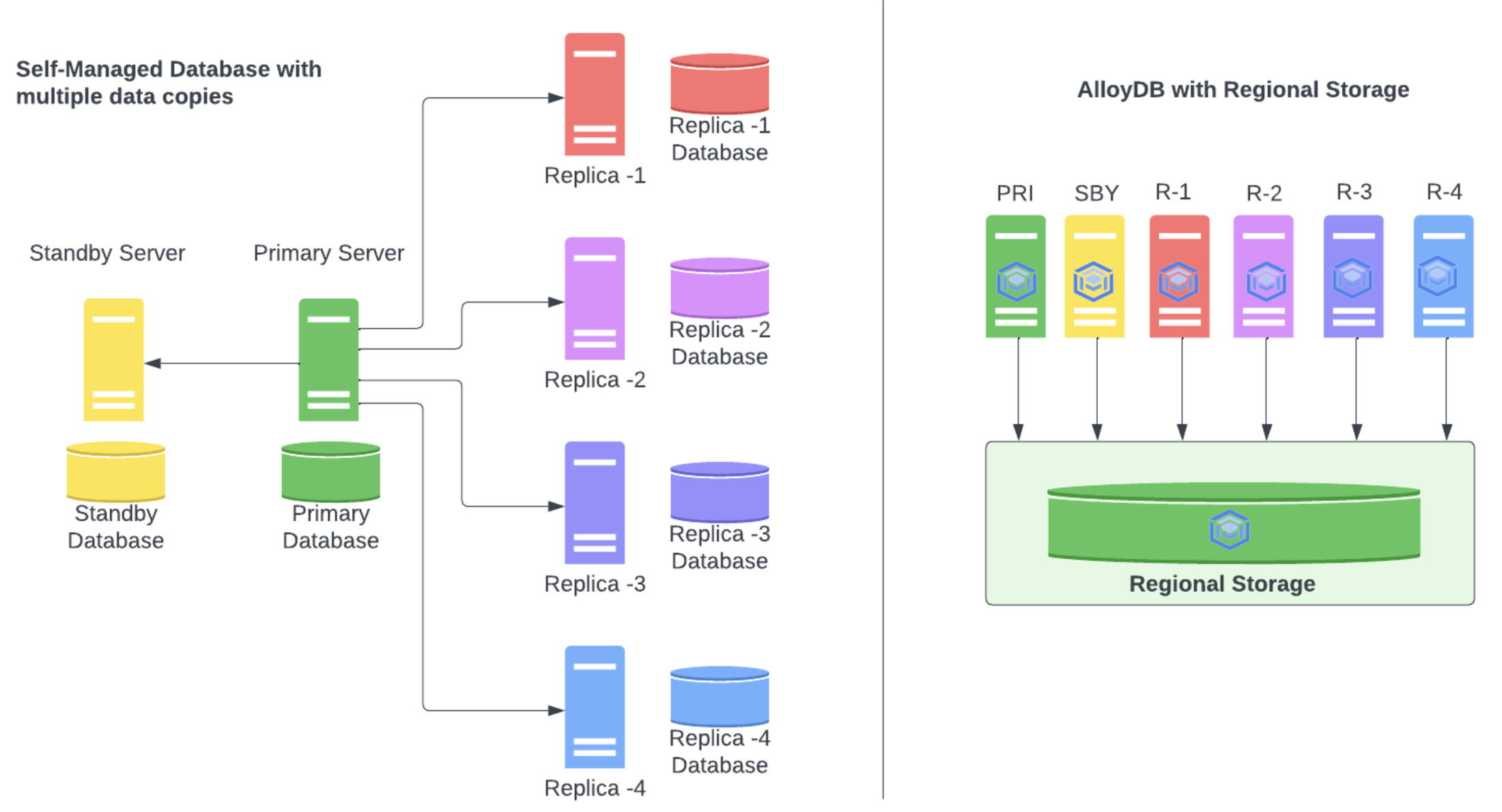
To understand AlloyDB’s strengths, it helps to look at its architecture. AlloyDB’s architecture is fundamentally different from a standard PostgreSQL setup. Traditional Postgres (and by extension, Cloud SQL for Postgres) uses a monolithic architecture: the database server and storage reside on the same VM or physical machine, and scaling usually means vertical scaling (bigger machine) or adding read replicas that each maintain a full copy of data. AlloyDB breaks this paradigm with a disaggregated, cloud-native design.
Key architectural features of AlloyDB:
- Disaggregated Compute and Storage: AlloyDB separates the PostgreSQL compute layer (the query engine nodes) from the underlying storage layer. Data is stored in a distributed storage service built by Google, rather than on local disks attached to a single server. This storage layer is highly available and shared across all nodes in an AlloyDB cluster. The benefit is independent scaling – you can scale up or down the compute (vCPUs/memory) or add/remove read nodes without moving or copying storage. Similarly, as your data grows, the storage layer expands automatically, without impacting the compute nodes. This design also improves failover times and read replica efficiency, since a promoted node or new replica can access the same data store immediately.
- Intelligent Storage with Log Processing: AlloyDB’s storage layer is not just a dumb disk; it’s a database-aware storage service. The system offloads many tasks to storage by using a log-based replication and processing mechanism. Whenever transactions are committed, the PostgreSQL WAL (write-ahead log) is ingested by the storage service, which handles replication and even some query-processing optimizations. This reduces I/O bottlenecks and can perform tasks like parallelizing reads or doing post-write processing in the storage tier. Essentially, AlloyDB leverages ideas similar to Aurora’s design, where the database engine pushes down work to a distributed storage layer (like applying log records to pages, etc.). The result is faster commits and quicker recovery/failover, since the storage layer keeps multiple copies of data across zones and can promote a new primary within ~60 seconds if the active node fails.
- Multiple Caching Layers: To maximize performance, AlloyDB employs caching at multiple levels of the stack. There’s an ultra-fast cache (using additional memory or possibly persistent memory/flash) that is provisioned automatically in addition to the instance’s memory. This cache stores hot data and reduces latency for frequent queries. Caching is tiered and adaptive – the system will automatically manage what resides in the instance memory versus lower-level cache or storage based on access patterns. These layers ensure that reads (and even some writes) are served quickly, contributing to AlloyDB’s high throughput.
- Hybrid Workload Optimization (HTAP): AlloyDB is designed for hybrid transactional/analytical processing. A standout feature is its columnar engine: frequently accessed tables or portions of data can be stored in a columnar format in memory for analytics. Analytical queries (e.g., aggregates, scans) on these columnar representations can be up to 100× faster than on the row-based storage. This happens transparently, so operational workloads can run analytics or reporting on live data without exporting it to a separate data warehouse. By contrast, traditional Postgres would struggle with heavy analytics on an OLTP database. AlloyDB’s approach allows one database to handle both OLTP and OLAP efficiently (hence HTAP). This is a differentiator against other managed Postgres services – for instance, Amazon Aurora does not have a built-in columnar analytic feature (Amazon typically pairs Aurora with Redshift or Aurora Materialized Views for analytics, whereas AlloyDB bakes it into the engine).
- Automated Management and AI Assistance: Being a managed service, AlloyDB handles many operational tasks automatically. This includes continuous backups and PITR, point-in-time recovery, automatic replication across AZs, patching and version upgrades with minimal downtime, and autoscaling recommendations. AlloyDB also integrates machine learning for maintenance – for example, it has adaptive vacuuming (to tune PostgreSQL’s vacuum process), and an index advisor that uses AI to suggest indexes based on your workload. These features reduce the manual tuning DBAs need to do. Cloud SQL has some automation as well, but AlloyDB extends it with more intelligence (the Gemini AI integration in AlloyDB can even help generate SQL and analyze queries via a studio interface ). Security is also handled with data encrypted at rest and in transit, and support for customer-managed encryption keys and IAM-based access control.
AlloyDB’s architecture represents a “next-gen” cloud database design, similar in spirit to Aurora, but with Google’s spin on it. By moving functionality out of the single Postgres instance into a distributed system (storage layer, caches, etc.), AlloyDB achieves higher performance, better fault tolerance, and easier scaling than a traditional Postgres deployment. Developers and architects don’t necessarily see all this complexity – they connect with a standard Postgres interface and SQL – but under the hood, AlloyDB is doing a lot to ensure your queries run fast and your data is always available.
AlloyDB vs. Cloud SQL (Google’s managed Postgres)
.png)
Google Cloud already offers Cloud SQL for PostgreSQL – a popular fully-managed database service. How is AlloyDB different? In short, Cloud SQL is a more traditional managed Postgres (or MySQL/SQL Server) suitable for general-purpose workloads, whereas AlloyDB is built for high-end, mission-critical workloads that demand extreme performance and scale. Google positions AlloyDB as the choice for the “most demanding enterprise workloads,” offering greater performance, availability, and scalability. By contrast, Cloud SQL focuses on ease of use and broad compatibility (supporting multiple database engines).
Some key differences between AlloyDB and Cloud SQL include:
- Architecture: Cloud SQL uses a traditional architecture where each database instance has its own compute and storage (with optional read replicas that each maintain a copy of the data). AlloyDB employs a disaggregated architecture – it separates the database compute (instances/nodes) from a shared storage layer. This means all instances in an AlloyDB cluster share a single, auto-scaling storage layer in the region. The storage is distributed across multiple zones for resiliency, and compute nodes can be added or removed independently. This design enables independent scaling of compute and storage – you can scale CPU/memory or add read instances without duplicating data. In contrast, scaling Cloud SQL often involves vertical scaling or adding read replicas that each keep a full copy of the data.
- Performance: AlloyDB’s custom engine and intelligent storage system provide significantly higher throughput and query performance than standard Postgres. It has multiple caching layers and optimized I/O management to accelerate reads/writes. It even includes a built-in columnar engine for analytics, allowing hybrid transactional/analytical processing (HTAP) on the same database with up to 100× faster analytic queries than vanilla Postgres. Cloud SQL’s performance is closer to a stock PostgreSQL setup – suitable for many workloads, but without AlloyDB’s extra performance boosters. For example, Google reports 4× higher transactional throughput on AlloyDB versus stock Postgres. Such improvements can translate to better application responsiveness and the ability to handle more concurrent users on AlloyDB.
- High Availability: Both services offer high availability configurations, but AlloyDB takes it further. AlloyDB provides a 99.99% availability SLA, even during maintenance, and can fail over or resize instances with minimal disruption (usually under one second of downtime). Its primary instance can be configured with an active/standby node pair for automatic failover, and read pool instances can handle reads continuously. Cloud SQL’s High Availability (HA) uses a primary instance with a standby in another zone; it offers strong uptime (Cloud SQL guarantees up to 99.95% SLA for HA instances) but may incur brief downtime during failover or maintenance windows. AlloyDB’s architecture also enables near-zero downtime maintenance by decoupling the database engine from underlying storage and by applying updates with minimal impact.
- Read Scaling: Scaling read throughput is easier with AlloyDB. You can add up to 20 read pool replicas that all share the same storage data, without needing to copy data for each replica. Because the storage layer is shared and synchronized, AlloyDB’s read replicas have very low lag and no extra storage cost. In fact, Google notes that regional read replicas have 25× lower replication lag than standard Postgres replicas under heavy load. Cloud SQL allows adding read replicas for Postgres, but each replica is essentially another instance with its own storage copy, which can introduce replication lag and additional cost. Failover and replica promotion in Cloud SQL may also be slower compared to AlloyDB’s design. AlloyDB’s distributed storage means replicas are lightweight and up-to-date, making horizontal scaling and failover much more efficient.
- Features and Extensions: Both Cloud SQL and AlloyDB are PostgreSQL-compatible and support many popular extensions. However, AlloyDB includes advanced features not available in Cloud SQL, such as the aforementioned columnar storage for analytics and AI integrations (e.g., built-in vector search via pgvector, and integration with Vertex AI for machine learning queries). AlloyDB’s engine also provides automated management features like adaptive autovacuuming, an AI-powered index advisor, and memory tuning. Cloud SQL provides a solid managed Postgres experience, but without these extra performance and AI capabilities. Additionally, Cloud SQL supports multiple database versions (and even MySQL/SQL Server), whereas AlloyDB focuses on PostgreSQL and keeps the engine updated – it doesn’t offer user-selectable Postgres versions but ensures compatibility and handles upgrades in-place.
Bottom line: Cloud SQL is a great managed service for everyday PostgreSQL use cases, especially if you need simplicity or multi-database support. GCP AlloyDB is aimed at those needing higher scale, performance, and HA – for example, large enterprise applications, heavy transactional systems, or hybrid workloads that blend OLTP and OLAP. It’s a closer analog to Amazon Aurora (as we’ll discuss next) in terms of engineering enhancements. Many organizations might start with Cloud SQL and later move to AlloyDB as their needs grow, and Google provides tools to migrate from Cloud SQL to AlloyDB relatively easily.
AlloyDB vs. Amazon Aurora
.png)
It’s natural to compare AlloyDB with Amazon Aurora (for PostgreSQL), since both are cloud-optimized Postgres-compatible databases. Aurora has been AWS’s flagship improved Postgres offering for years, and Google clearly designed AlloyDB in the same vein, aiming to outperform stock Postgres and offer a cloud-managed experience for demanding workloads. So, how do they differ?
- Architecture and Design: Both AlloyDB and Aurora use a distributed storage layer and decoupled compute. In Aurora, the PostgreSQL instances (writers/readers) offload storage to a multi-AZ distributed volume that keeps six copies of data across three AZs. AlloyDB’s architecture is very similar conceptually: the primary and read pool nodes operate against a regional storage layer that replicates data across zones for durability. Both systems use the database’s WAL (write-ahead log) to replicate and apply changes to storage nodes, enabling fast crash recovery and failover. The net result is that neither AlloyDB nor Aurora requires full data copies for read replicas – read replicas in both share the same storage, making them efficient to add. One subtle difference is that Google’s implementation touts multiple caching layers and in-memory columnar processing for analytics, which Aurora (PostgreSQL) does not natively provide. Aurora focuses on speeding up OLTP and read scaling, whereas AlloyDB also emphasizes HTAP capabilities with its columnar engine. Both aim for high availability; AlloyDB offers a 99.99% SLA, while Amazon Aurora Postgres offers 99.99% as well (Aurora automatically replicates across 3 AZs and can fail over typically in <30 seconds). In practice, the architectures are more alike than different – it’s the performance tuning and extra features that set them apart.
- Performance Claims: Amazon Aurora (PostgreSQL) is known to claim roughly 3× the throughput of standard PostgreSQL on AWS, due to its storage optimizations and caching. Google’s AlloyDB claims >4× the throughput of standard PostgreSQL for transactions. While these claims come from different benchmarks, they suggest AlloyDB is positioning itself as equal or better in performance compared to Aurora. In addition, AlloyDB’s 100× faster analytics (thanks to the columnar format) has no direct equivalent in Aurora’s feature set. So, for purely transactional workloads, the two are likely in the same class, but for mixed workloads or heavy read analytics on operational data, AlloyDB could have an edge by not forcing you to use a separate analytics DB. It’s worth noting that both services maintain full PostgreSQL compatibility, so performance gains are achieved under the hood – you don’t have to rewrite queries to benefit. The actual performance for a given application may vary, but both AlloyDB and Aurora significantly improve on what vanilla Postgres can do on a single VM.
- Pricing Model: One of the biggest differences is how you pay for storage I/O. AlloyDB pricing is transparent and has no separate I/O charges. You pay for compute (vCPUs and RAM of your instances), storage capacity used, storage backups, and networking, but you are not charged per read/write operation. In contrast, Amazon Aurora’s pricing includes I/O throughput charges (per million requests to the storage layer), which can make costs harder to predict and can add up if you have I/O-intensive workloads. Google explicitly highlights this distinction: AlloyDB has “no opaque I/O charges” and no proprietary licensing costs. Everything is billed in a straightforward resource-based manner, which many customers find more predictable. Additionally, adding read replicas in AlloyDB does not increase your storage cost (since replicas share storage), whereas in Aurora, you also don’t pay extra for storage for replicas (they also share storage) – so that aspect is similar. Where costs diverge is if your workload is very read-heavy or write-heavy: Aurora’s per-I/O fees might make it pricier at scale, whereas AlloyDB’s cost would mainly scale with the size of instances and data. For example, the Web3 company Galxe migrated from Amazon Aurora to AlloyDB and cut their database costs by 40%, largely because Aurora’s costs for read/write operations were so high for their workload . With AlloyDB’s flat pricing, they saved money while getting comparable (or better) performance.
- AlloyDB Omni vs. Aurora: Another differentiator is deployment flexibility. Google Cloud offers AlloyDB Omni, a downloadable edition of AlloyDB that you can run outside of Google Cloud – whether on-premises, on other clouds, or at the edge. This gives customers a kind of “hybrid” or multi-cloud capability with AlloyDB, using the same engine in self-managed environments. Aurora, on the other hand, is an AWS-managed service that runs only on AWS (though Amazon has Aurora on Outposts for on-prem via AWS hardware, it’s not a portable software you can run on any infrastructure). AlloyDB Omni means you could, for instance, develop or test locally on your laptop with AlloyDB, or deploy AlloyDB in a private data center that needs to remain off-cloud, then later move to the fully managed service on GCP – all while using the same database technology. This “run anywhere” philosophy is a key part of AlloyDB’s value proposition, whereas Aurora locks you into the AWS ecosystem. (We’ll describe AlloyDB Omni more in the next section.)
AlloyDB vs Aurora is a battle of two very similar approaches from Google and Amazon. Both give you a PostgreSQL that’s souped-up for the cloud. If you are already on Google Cloud or prefer Google’s ecosystem, AlloyDB is the natural choice, offering equal or better performance and a more predictable cost structure. If you’re on AWS, Aurora is the incumbent option. For a neutral comparison: AlloyDB’s standout features are its HTAP capability, lack of I/O fees, and multi-cloud flexibility. Aurora’s strengths include its maturity and deep integration with other AWS services. But from a pure technology standpoint, Google AlloyDB has emerged as a formidable competitor to Aurora in the cloud Postgres arena.
AlloyDB Omni – “AlloyDB Anywhere”

One of the most interesting aspects of AlloyDB is AlloyDB Omni. This is a downloadable, self-managed version of AlloyDB that runs anywhere – on-premises, in other clouds like AWS/Azure, or even on a developer’s laptop. AlloyDB Omni is powered by the same database engine as the managed AlloyDB service on GCP, which means you get the same PostgreSQL compatibility and performance enhancements (the vectorized engine, adaptive algorithms, etc.) outside of Google Cloud.
Why did Google create AlloyDB Omni? It addresses scenarios where you can’t (or won’t) run your database in Google’s cloud but still want the benefits of AlloyDB’s tech. For example, you might have regulatory or data sovereignty requirements that force you to keep data on-prem, or you might have an edge use-case (say, in a retail store or remote location) where the database needs to run locally without reliable cloud connectivity. AlloyDB Omni lets you modernize those environments using AlloyDB’s engine in place, perhaps as a first step before later migrating to the cloud. It’s also useful for multi-cloud strategies – you could run AlloyDB Omni on other cloud providers’ VMs, enabling a consistent database across clouds.
Key points about AlloyDB Omni:
- 100% PostgreSQL-compatible: Like the cloud version, Omni is fully Postgres-compatible. Applications can connect with standard PostgreSQL drivers and work unchanged. It supports the same SQL features, extensions, and flags. This means you could develop against AlloyDB Omni locally, and later transition to AlloyDB on Google Cloud with minimal friction.
- Performance Boosts On-Prem: AlloyDB Omni brings the performance gains of AlloyDB to self-managed infrastructure. Google states that in tests, AlloyDB Omni is over 2× faster than standard PostgreSQL for transactional workloads, and up to 100× faster for analytical queries (since Omni includes the same in-memory columnar acceleration). These improvements can be realized on whatever hardware you run Omni on (commodity x86 servers, etc.), effectively giving you a “cloud-optimized” Postgres in your own data center.
- Included Features: Omni includes features like the AlloyDB columnar engine for analytics, AI-powered index recommendations, automatic memory management, and more. It’s essentially the same database engine that powers the cloud service. One thing to note: because Omni is self-managed, you are responsible for operating it (setting up replication, backups, HA clustering, etc.) – Google provides guides and even a Kubernetes Operator to help manage AlloyDB Omni deployments. Google also offers enterprise support for Omni (with a support subscription), so you can get 24/7 support and updates even if running it outside GCP.
- License and Cost: AlloyDB Omni is not open-source; it’s provided as a Google product download. However, Google highlights that Omni can be a “fraction of the cost of legacy databases” for modernization. In other words, if you’re paying large licensing fees for an old-guard database (like Oracle or a proprietary system) on-prem, switching to AlloyDB Omni could save money while still giving you enterprise-grade performance (with Google’s support behind it). The pricing model for support is not publicly listed (you’d contact sales for an enterprise quote ), but the value proposition is avoiding big license contracts. For purely experimental or development use, there’s a free Developer Edition of AlloyDB Omni available as a downloadable VM image, so you can try it out easily.
In practice, AlloyDB Omni provides a nice bridge for hybrid cloud setups. You could run Omni on-prem for sensitive systems and use managed AlloyDB in Google Cloud for cloud-deployable systems, and they’d be using the same underlying technology. Data migrations can be easier (using standard Postgres tools or Google’s Database Migration Service) between Omni and cloud, since the compatibility is the same. This kind of flexibility is something Amazon Aurora doesn’t offer (Aurora can’t be run outside AWS), so AlloyDB Omni is a differentiator for Google in courting customers who want cloud benefits without full cloud lock-in.
Pricing and Cost Considerations

When evaluating any database service, cost is a crucial factor. AlloyDB’s pricing model is designed to be transparent and predictable, especially in contrast to some competitor models (where unpredictable I/O or licensing costs can surprise users). Let’s break down how AlloyDB pricing works and what to consider for cost:
- Compute (vCPU and Memory): You pay for the compute capacity of your AlloyDB instances per hour, based on the number of vCPUs and the amount of RAM. This is similar to how you’d pay for VM instances. AlloyDB allows quite large instance sizes (up to 128 vCPUs and 864 GB RAM per node). If you use a High-Availability primary, you have two nodes (primary + standby), so effectively double the vCPU/RAM cost for the primary instance. Read pool instances can have multiple nodes (up to 20), and you’ll pay for each node’s vCPU/RAM. Prices vary by region but are roughly on par with high-performance VM pricing. Google also offers committed use discounts (CUDs) for AlloyDB – e.g., committing to 1-year or 3-year usage can reduce the effective hourly cost of vCPU and memory (commonly by 30-50%). This can significantly reduce cost for steady workloads, similar to how one would use reserved instances on AWS.
- Storage and I/O: Storage is charged per GB-month for the data stored in the AlloyDB cluster. The good news is you only pay for storage used (it auto-scales, so there’s no pre-allocation fee for a large disk you aren’t using). Moreover – and this is important – there are no additional storage I/O charges. Many database services (like AWS Aurora) charge for the number of reads/writes to storage, but AlloyDB does not. Google has emphasized this as a customer-friendly aspect: “no opaque I/O charges”. This means if your application performs a lot of disk reads/writes, you won’t get a separate bill line-item counting each million I/Os. Cost will scale mainly with the size of your data and the size of your instances, not directly with how busy the database is. Additionally, because AlloyDB’s read replicas share the same storage, adding read instances does not duplicate storage costs (you’re still only charged for one copy of the data). This is a cost advantage over architectures that require multiple full copies for scaling reads.
- Backups: Automated backups and point-in-time logs are stored in Google Cloud Storage and charged per GB-month (at a lower rate than live storage). AlloyDB’s backup storage pricing is usually quite nominal unless you retain a lot of backup data. The pricing page details how backup storage beyond the free retention (if any) is billed. Keep in mind that backups in AlloyDB are incremental and managed, so you pay only for the delta changes and the total backup footprint.
- Network Egress: Network costs are similar to other GCP services – any data egress from the database to another region or outside of Google Cloud will incur bandwidth charges. If your application servers are in the same region and on Google Cloud, you typically won’t pay for internal traffic. But cross-region replication (for a secondary cluster in another region) will generate some network usage (charged at inter-region rates). This is not AlloyDB-specific, just general cloud network billing to be aware of.
- Licensing: There is no separate license fee for AlloyDB. Unlike some databases (e.g., Oracle or MS SQL Server) where you might pay for a software license, AlloyDB is open-source Postgres–based and the service cost is all-inclusive. Google is essentially charging for the infrastructure and service, not the database engine. So you don’t have to worry about any per-core license on top of the instance cost.
- Cost Comparisons: According to Google, AlloyDB provides better price-performance than many alternatives. They claim 2× better price-performance vs. self-managed PostgreSQL – meaning that for the same money, you’d get roughly double the performance on AlloyDB compared to running Postgres yourself on VMs (this accounts for the performance gains we discussed). Of course, this is a general claim; actual results depend on workload. But early case studies are promising: for example, **Galxe’s migration from Aurora to AlloyDB** not only improved performance but also cut costs by 40%. Those savings came from eliminating Aurora’s I/O charges and using AlloyDB’s transparent pricing to their advantage. If you currently use Cloud SQL, you might find AlloyDB a bit more expensive on paper for the same instance size (because AlloyDB’s infrastructure is more advanced). However, AlloyDB can handle more workload per vCPU in many cases, which could mean you need fewer vCPUs or fewer replicas to achieve your performance goals, thus balancing out costs. And if your workload is I/O-heavy, AlloyDB’s lack of I/O charges might make it cheaper at scale. It’s wise to estimate your workload: Google provides a pricing calculator where you can model AlloyDB clusters vs. Cloud SQL or Aurora setups.
- Committed Discounts and Autoscaling: If you have steady usage, leverage the committed use discounts for significant savings. If your usage is spiky, you might consider using fewer baseline resources and scaling up when needed – AlloyDB allows instance scaling (even auto-scaling of read pools) relatively easily. You could save costs by running smaller instances during off-peak and scaling up for peak (though note that instance size changes do incur a very brief downtime on AlloyDB – but read pools can be added/removed dynamically with no downtime). Always monitor your utilization; AlloyDB’s Query Insights and performance monitoring can help identify if you’re over-provisioned.
AlloyDB’s cost model is designed to be predictable (no surprise fees) and scales with usage. It addresses a common complaint about cloud databases – complex billing – by keeping it straightforward: CPU/Memory, storage, backups/network. There are no hidden fees for features either; things like high-availability, read replicas, columnar engine, etc., are part of the service (you just pay for the resources they use). This transparency, combined with AlloyDB’s performance efficiency, can make it quite cost-effective for heavy workloads when compared to both self-managed setups and competitors like Aurora. However, for smaller or light workloads, Cloud SQL or simpler setups might be cheaper if you don’t need AlloyDB’s extra horsepower. It’s all about using the right tool for the job – and Google is positioning AlloyDB as the tool you choose when you need cloud-scale Postgres without breaking the bank.
Monitor Your AlloyDB Spend Spend with Cloudchipr
AlloyDB projects is just the start—actively managing cloud spend is crucial for staying on budget. Cloudchipr provides an intuitive platform that delivers multi-cloud cost visibility, helping you monitor your AlloyDB usage, eliminate waste, and optimize resources across AWS, Azure, and GCP.
Key Features of Cloudchipr
Automated Resource Management:
Easily identify and eliminate idle or underused resources with no-code automation workflows. This ensures you minimize unnecessary spending while keeping your cloud environment efficient.
Receive actionable, data-backed advice on the best instance sizes, storage setups, and compute resources. This enables you to achieve optimal performance without exceeding your budget.
Keep track of your Reserved Instances and Savings Plans to maximize their use.
Monitor real-time usage and performance metrics across AWS, Azure, and GCP. Quickly identify inefficiencies and make proactive adjustments, enhancing your infrastructure.
Take advantage of Cloudchipr’s on-demand, certified DevOps team that eliminates the hiring hassles and off-boarding worries. This service provides accelerated Day 1 setup through infrastructure as code, automated deployment pipelines, and robust monitoring. On Day 2, it ensures continuous operation with 24/7 support, proactive incident management, and tailored solutions to suit your organization’s unique needs. Integrating this service means you get the expertise needed to optimize not only your cloud costs but also your overall operational agility and resilience.
Conclusion
Google AlloyDB is a major step forward for PostgreSQL in the cloud, combining familiar Postgres features with Google’s high-performance, cloud-native architecture. Its disaggregated design enables elastic scaling, high availability, and built-in analytics, making it ideal for demanding workloads that need both fast transactions and real-time analytics. Positioned between Cloud SQL and Cloud Spanner, AlloyDB is the clear choice when your workload outgrows traditional managed Postgres, but you want to stay in the PostgreSQL ecosystem. Fully managed and tightly integrated with Google Cloud, AlloyDB reduces operational overhead and offers flexible deployment, including hybrid and multi-cloud options via AlloyDB Omni. For teams facing the limits of standard Postgres, AlloyDB delivers the scale, speed, and automation needed for modern data-intensive applications


