Observability vs Monitoring: What’s the Real Difference?
.png)
Introduction
Picture this: you’ve spent years neck-deep in complex systems, only to find the same head-scratcher popping up in meetings again and again. Observability vs. monitoring – they sound like interchangeable buzzwords, right? I mean, they both deal with keeping systems in line… so, same difference? Well, not exactly. Monitoring basically pipes up to tell you if something’s busted, whereas observability dives deeper to show what in the world is happening under the hood and why it’s behaving that way. It’s a subtle distinction that’s become hugely important as modern software scatters into countless microservices and cloud environments across the globe.
Now, we won’t just drop that bombshell and leave you hanging. In this piece, we’ll tap into some hard-earned industry wisdom (think decades of on-call nights and lessons learned the hard way) to clarify what observability vs monitoring really means. We’ll see how telemetry (that stream of data your systems spew out) fits into the puzzle, and why nailing this difference is crucial if you want your systems to stay healthy and your on-call phone to stay quiet (well, quieter).
What Is Monitoring?
.webp)
Let’s start simple: monitoring is basically the act of keeping watch on a bunch of pre-chosen system metrics and logs so you can get a heads-up when something starts acting fishy. It’s an active process, not some mystical property of the system. We deliberately set up instruments and checks to continuously ask one big question: “Is this system working correctly right now?” Think of a car dashboard: we decide which warning lights to include (engine temperature, oil level, battery) and then we keep an eye on them. Classic monitoring works the same way. We collect data points like CPU usage, memory consumption, error rates, or how many requests are zipping through per second. Then we draw lines in the sand – thresholds and alert rules. If something strays out of bounds (say the error rate shoots through the roof or available disk space drops to near-zero), our monitoring tools jump up and down to get our attention.
In plainer terms, monitoring lets you know when something is wrong. It’s inherently reactive. The alarm bells go off after an issue appears, and only for the specific conditions we anticipated and set up ahead of time. Picture a simple scenario: a dashboard starts flashing red because a web server went down or a database query kept timing out. You get that dreaded ping on your phone at 3 AM, telling you “Hey, something broke!” Sure enough, the logs (think of them as the system’s running diary) might show a trail of events leading up to the blow-up, giving you hints about what happened right before things went south. But here’s the thing — traditional monitoring zeroes in on known failure modes. It dutifully watches the spots you’ve told it to watch, which means it can totally miss the weird stuff that falls outside those predefined conditions.
Now, monitoring tools and practices have been around forever (at least in tech years). From the old-school days of basic uptime pingers to today’s fancy dashboards that track everything from infrastructure vitals to application performance, monitoring has been our first line of defense. We have infrastructure monitoring (CPU, memory, network usage – the whole hardware heartbeat), APM or application performance monitoring (keeping tabs on response times, throughput, and all that jazz), even user-experience monitoring (like those scripts that watch what real users experience on your website). All these tools share one mission: spot the oddballs or known “red flags” in how the system’s behaving so engineers can jump on issues quickly, hopefully before users notice.
But let’s be honest: monitoring has a big blind spot. It only watches what you tell it to watch. It requires you to know ahead of time what metrics or events are the harbingers of trouble. If something goes wrong in a completely unexpected way — some scenario you never even thought to measure — plain monitoring is likely to shrug its shoulders and say “I dunno, everything I was watching looks fine.” And that, my friends, is exactly where observability comes into play, swooping in to cover those unknown unknowns that monitoring alone might miss.
What Is Observability?
If monitoring is the night watch guard, observability is the clever detective working behind the scenes. It’s a broader, more proactive philosophy. In plain terms, observability is the ability to figure out what’s going on inside a system by looking at the clues it leaves on the outside. (That’s the textbook definition: inferring internal state from external outputs – fancy, huh?) Unlike monitoring, which is a thing you do, observability is more of a property that a system can have and a mindset that engineers adopt. Monitoring might casually ask, “Hey, everything okay over there?” Observability is the one asking, “What exactly is happening inside this system and why is it doing that?”. An observable system spills out rich data about itself – logs, metrics, traces, events – and with the right approach, you can probe that data to answer almost any question about the system’s behavior, even those crazy questions you never thought to ask in advance.
In practice, observability means hoarding a wide range of telemetry data (metrics, events, logs, distributed traces – basically any signal you can get) and then mining it for insights using powerful tools (often supercharged with advanced analytics or a dash of AI). This approach is decidedly proactive. It doesn’t wait for a catastrophe to scream; it sniffs around and spots patterns or oddities that no one explicitly told it to watch for, letting your team catch problems before they whack your users in the face. For example, imagine your observability platform notices a spike in error logs right after the latest microservice update. It then traces that spike down through your services and reveals, say, a specific database query in one service that’s suddenly locking everything up and causing a cascade of failures. That’s the kind of deep sleuthing that a simple monitoring alert (“hey, error rate’s high!”) wouldn’t do on its own.
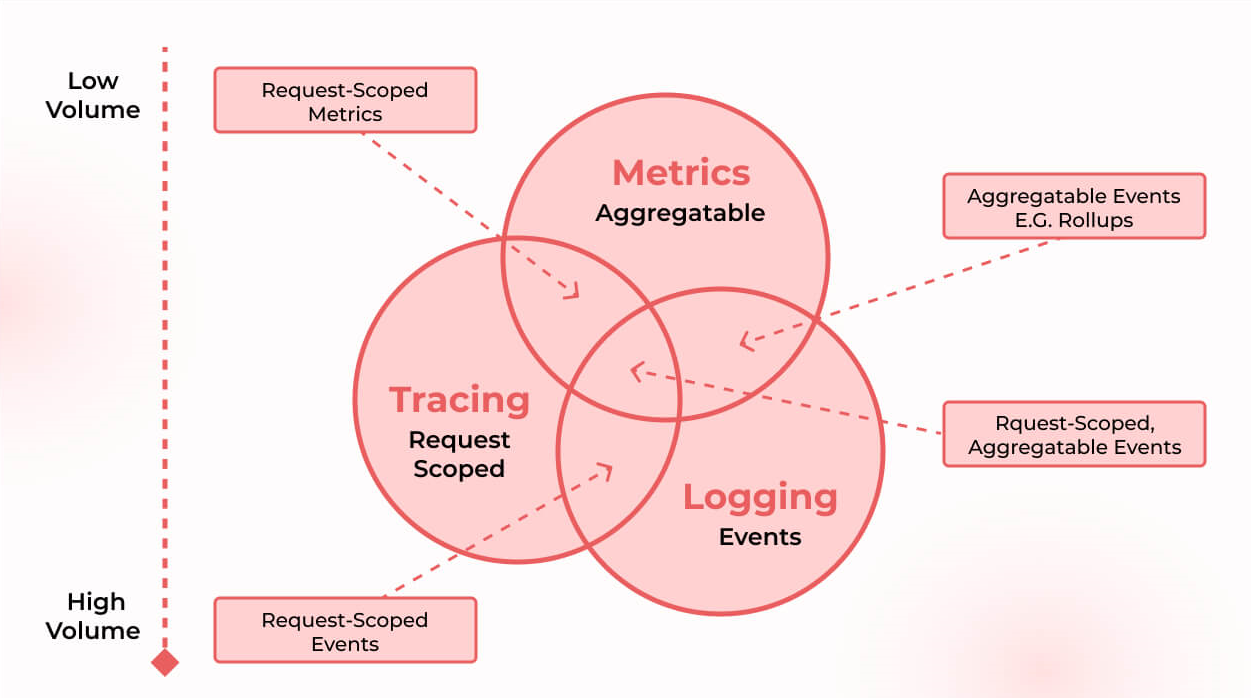
People often talk about the “three pillars” of observability: logs, metrics, and traces. Here’s a quick analogy: metrics are like the vital signs of your system (heart rate, blood pressure, temperature), logs are like the detailed diary entries (what exactly happened and when), and traces are the full play-by-play story of a request or transaction as it snakes its way through all your microservices. When you can correlate all three of those (and often you throw in other data too – maybe user behavior events or security signals, whatever gives insight), you end up with a pretty darn comprehensive picture of what’s going on. The key is that observability tools chew on all this telemetry to answer the why and how of issues, not just the what. And modern observability platforms are getting spooky smart: many leverage machine learning (buzzword alert: AIOps) to flag the truly weird “unknown unknowns” – patterns no human thought to look for – and sometimes even suggest fixes on the spot.
One thing to keep in mind: observability isn’t a magic feature you toggle on one afternoon. You have to design it into your systems from the ground up (or steadily retrofit it in). That means writing your applications so they emit detailed telemetry about their inner workings and cultivating a culture where engineers feel free to poke around, ask ad-hoc questions, and explore the data without a predefined script. When you get it right, observability offers a holistic, real-time view into your complex stack. It lets you unravel bizarre, one-in-a-million problems on the fly and even anticipate issues before they blow up in your face. In short, observability makes you feel less like you’re flying blind and more like you have X-ray vision into your production environment – a comforting thought when things get crazy.
Monitoring vs Observability: Key Differences
Monitoring and observability are like two sides of the same coin — they work together, but they aren’t identical twins. In fact, you can think of monitoring as a subset (or a crucial ingredient) of observability. Let’s break down some key differences, and see how these concepts complement each other:
- Scope & Focus: Monitoring zeroes in on the known knowns. It watches the specific metrics or conditions you decided to track (e.g. “Alert me if CPU > 90%” or “ping me when HTTP error rate spikes”) and basically asks “Is the system working okay right now?”. It’s fundamentally reactive — it highlights problems after they’ve already happened (because you set a rule for it beforehand). Observability, by contrast, casts a much wider net, worrying about the unknown unknowns. It’s asking, “Why is the system acting like this?” and “What’s going on in there?”, which makes it a more proactive approach that can even predict or prevent issues rather than just react to them.
- Data & Inputs: Monitoring tends to live off a limited diet of data — mostly a handful of metrics and maybe some basic log checks, often looked at in isolation. Observability, on the other hand, feasts on MELT data (that stands for Metrics, Events, Logs, and Traces) and sometimes even more. It correlates all those data points to give you richer context. In short, monitoring captures and displays data, while observability churns through that data to discern your system’s health and dig up root causes. Think of it this way: monitoring will show you the numbers (CPU at 95%, error count 1000, etc.), whereas observability connects the dots between those numbers to tell you what they mean.
- Problem Solving: When a basic monitoring alert fires, you often end up doing a lot of manual legwork to figure out what’s up. Monitoring might yell “Something’s wrong on Server A!” but it won’t automatically tell you why. So you start correlating metrics, checking logs, scratching your head… By contrast, observability is built for rapid detective work. It provides context across distributed components, so it can help pinpoint what’s breaking and why, often automatically or with just a few clicks. For example, monitoring might show that a server is overloaded (useful to know, sure). Observability would take it a step further and reveal which service call or upstream event triggered that overload, and maybe even highlight how to fix it. It’s the difference between knowing the symptom versus diagnosing the disease.
- Use Cases & Complexity: In a small, simple, static environment, plain monitoring might be enough to keep things humming. But the systems we deal with today are anything but simple. Modern cloud-native setups are insanely complex — ephemeral servers, dozens of microservices, networks-of-networks. As one expert neatly said, “monitoring shows the effect (symptom), observability helps find the cause.” In these convoluted environments, observability becomes essential. You just can’t foresee every possible failure mode ahead of time. Observability shines at dissecting those complex, interdependent failures that would have a basic monitoring setup throwing its hands in the air. It’s like having an investigative journalist for your system, digging into connections you didn’t even know existed.
In summary, monitoring tells you when something is wrong, while observability helps you understand what’s wrong, why it happened, and even how to fix it. The two go hand in hand. Smart reliability engineering pairs comprehensive monitoring (the eyes and ears of your operations) with deep observability (the brain making sense of all the input). In practice, you want monitoring to catch the initial whiff of trouble, and observability to dive in and explain the story behind it. That combination keeps your systems robust and your on-call engineers a whole lot happier.
Observability vs Monitoring vs Telemetry
There’s another term that often jumps into this conversation: telemetry. So how does telemetry relate to monitoring and observability? The quick rundown: telemetry is the raw data, whereas monitoring and observability are what you do with that data.
- Telemetry: This refers to all those metrics, logs, traces, and other signals your systems emit – basically the raw feed of information that we collect and send off for analysis. It’s the foundation of everything: without telemetry, you’ve got nothing to monitor and no data to make your system observable. For instance, a web application might spit out telemetry like the duration of each user request, error log entries when something goes wrong, and trace spans that follow a request through all the microservices it touches. Modern standards like OpenTelemetry have emerged to help unify and standardize how we gather this kind of data across different apps and services (so you’re not dealing with a dozen different formats).
- Monitoring (uses telemetry): Monitoring takes that telemetry data and puts it to work. It’s essentially the act of watching specific telemetry streams and setting up rules to alert us when things look off. In other words, we use telemetry to track known conditions and fire off alarms based on predefined thresholds. For example, you might monitor a CPU usage metric (telemetry) and tell the system to warn you if it stays above 90% for 5 minutes. Monitoring is basically an application of telemetry – it’s how we leverage those raw metrics and logs to catch the issues we expect might happen.
- Observability (built on telemetry & monitoring): Observability steps in to make sense of all that telemetry on a broader scale. It’s about correlating and analyzing diverse data points to let us explore problems that we didn’t explicitly anticipate.
One important note: simply hoarding mountains of telemetry doesn’t automatically give you observability. You need the right tools and practices to squeeze meaning out of that data. Observability is all about using telemetry effectively – turning raw data into real insight about your system. And conversely, even good old monitoring can only be as good as the telemetry feeding into it (you can’t get an alert for something you never measured!). Ultimately, all three – telemetry, monitoring, and observability – work together in harmony to give you visibility and understanding of what’s going on in your tech environment.
Monitoring vs Observability: Example in Practice
All the theory aside, it helps to see a concrete example of how monitoring and observability play out differently in real life. Consider a scenario in the e-commerce world:
A major retailer’s website was mysteriously losing sales – customers were complaining that their orders kept failing here and there – yet the site itself never actually went down. The traditional monitoring in place was only checking the high-level basics: ping the site to make sure it’s up, maybe load the homepage to see that it responds. By those measures, everything looked peachy. The site was “up” (all green lights on the dashboard), so the monitors stayed quiet. If a server had crashed outright, the team would’ve gotten an alert, but in this case, the usual uptime alarms didn’t catch a thing.
Behind the scenes, though, a lot of customers were unable to check out due to a hidden backend glitch. This is where observability swooped in to save the day. Using an observability-driven approach, the retailer’s engineers started gathering detailed traces and logs for each user’s journey through the maze of microservices that handle order processing. And lo and behold, they discovered a couple of smoking guns: for one, the credit card payment service was intermittently not responding (imagine half the credit card transactions just timing out), and on top of that, an inventory microservice had a subtle bug that occasionally prevented items from being reserved properly. These were exactly the kinds of issues that basic monitoring didn’t catch because none of the high-level pings failed – the website was still up, it just wasn’t fully functional. Armed with this insight, the team zeroed in on those components, patched the bugs, and rescued a bunch of potentially lost orders (and probably saved a few careers in the process).
Puma, the athletic footwear brand, had a similar “aha” moment. Their old monitoring setup basically told them if the e-commerce site was up or down, and not much else. It missed all sorts of deeper problems – like customers unable to place orders because of an inventory service error or a payment gateway glitch. Those failures didn’t trigger the simple uptime monitors, so they flew under the radar and translated into lost sales. After Puma’s team adopted modern observability tools, they could suddenly see these hidden failures in vivid detail. Instead of just a green checkmark saying “site is up,” they could pinpoint: hey, the checkout service is failing for customers in Europe or the new release from two hours ago is causing 5% of product searches to error out. With that kind of visibility, they were able to fix issues quickly rather than scratching their heads while revenue quietly bled away. It drives home the point: monitoring might tell you the website is online, but observability tells you whether the business is actually working as intended. Uptime alone isn’t a guarantee that users can complete their purchases or tasks successfully.
So the moral of the story: an observable system gives you granular visibility to tell the difference between “everything is technically running” and “users are having a good experience.” Monitoring provides those basic signals (and yes, they’re super important for catching the obvious issues fast), but observability provides the understanding behind those signals. In practice, you really want both. Use monitoring to snag the low-hanging fruit of failures quickly, and use observability to troubleshoot the gnarlier problems and keep improving your system over the long haul.
How Cloudchipr Enhances Observability and Monitoring

Observability and monitoring can quickly become costly and complex, scattering data across multiple dashboards and manual processes that drain both budget and time—this is precisely where Cloudchipr shines by unifying live metrics, AI-driven insights, and automated FinOps workflows into one intuitive platform.
- Real-Time Dashboards: Visualize, track, and predict cloud costs in real time across AWS, GCP, and Azure with interactive widgets that highlight both high-level trends and granular charge details.
- Live Usage & Management: Monitor live resource metrics—CPU, memory, network, and more—directly alongside cost data. Take actions, send Slack alerts, or open tickets without ever leaving the platform.
- Resource Explorer: Slice and dice your multi-cloud spend in seconds, drilling down by account, region, service, or tag to pinpoint exactly where inefficient costs are mounting.
- AI Agents: Leverage built-in AI agents that analyze cluster and resource telemetry, flag anomalies, explain unexpected spend patterns, and even suggest or trigger optimization workflows on your behalf.

- No-Code Automations: Build powerful “if-this-then-that” workflows to automatically remediate waste—clean up idle resources, enforce tagging policies, or notify the right teams when budgets drift.
.svg)
- Kubernetes Monitoring: Gain fine-grained observability into container workloads with custom conditions and alerts for under-utilization or cost-inefficient usage in your clusters.
.png)
- Dimensions: Define dynamic cost-allocation rules—dimensions, categories, and virtual tags—that automatically map every dollar to its rightful team, project, or application for rich, context-aware insights.
- Anomaly Management: Detect, analyze, and resolve cost anomalies effortlessly. Customize anomaly rules, automate alerts, and tackle unexpected spend events before they become budget busts.
- Reporting & Analytics: Generate one-click reports and dashboards, share them across teams, set budgets, and forecast future spend—all from a single pane of glass.
- Commitment Alerts: Receive real-time notifications for expiring reservations and commitments—so you never miss a renewal window or pay on-demand prices by accident.
By weaving monitoring and observability together, Cloudchipr ensures you not only detect cost issues as they happen but also diagnose root causes and automate fixes—empowering your FinOps practice to run smoothly, predictably, and cost-efficiently.
Final Thoughts
At the end of the day, the whole “observability vs monitoring” debate isn’t about choosing one and ditching the other – it’s about knowing what each brings to the table and how they work together. Monitoring gives you the basic pulse of your system, answering the immediate what’s wrong in terms of known red flags. Observability gives you the X-ray vision to dig into why things are acting up and to spot issues you didn’t even know you should be looking for. As our systems become ever more complex and distributed, having strong observability on top of solid monitoring is moving from “nice-to-have” to absolutely essential for keeping things running smoothly.
So if you’re on a mission to make your systems more reliable, here’s our advice: use monitoring to grab the low-hanging fruit – the obvious, known issues – and invest in observability to tackle the thornier, mysterious problems and to drive continuous improvement. With the right blend of both, you’ll catch incidents faster, troubleshoot them with more confidence, and maybe even prevent some incidents entirely by spotting weird patterns before they escalate. In a world where uptime, performance, and user experience are directly tied to business success, the one-two punch of observability + monitoring (all fed by good telemetry data) is your ticket to building robust, resilient, insight-rich systems.
Remember, embracing observability doesn’t mean tossing monitoring out the window; it means supercharging it. By leveraging both, you ensure that when (and we all know it’s “when,” not “if”) something goes wrong, you won’t just get an alert that it happened – you’ll also have the tools and information to understand it and fix it, ideally before your users even notice the hiccup. That’s the ultimate goal: fewer frantic firefights at 2 AM, more foresight to avoid issues, and a whole lot more happy customers (and happier engineers, too).
Platforms like Cloudchipr gently bridge these two disciplines in a single FinOps-focused interface—melding real-time performance and cost monitoring with insightful analysis—so you can spot anomalies, dig into root causes, and act decisively without context-switching between tools.


