AI Cost Optimization: A Practical Guide for Engineering, AI, and FinOps Leaders

Introduction
The "AI at any cost" era is officially over.
For the past few years, organizations have been willing to absorb rising AI spend as the price of staying competitive. Experimentation was encouraged, budgets were flexible, and the CFO's questions were soft. That dynamic has shifted. Boards are asking harder questions. FinOps teams (98% of whom now manage AI spend, up from just 31% two years ago) are being asked to bring the same discipline to AI that they brought to cloud infrastructure. And engineering leaders are finding that the systems they built in production cost far more to run than anyone planned.
The challenge is real: average monthly AI spending reached $85,521 per organization in 2025, a 36% jump from 2024, and the proportion of companies spending over $100K per month has more than doubled. Meanwhile, nearly half of IT leaders estimate that more than 25% of their cloud spend goes to waste, and AI workloads are accelerating that problem.
The good news is that AI cost optimization is tractable. Teams that treat it as an engineering discipline, not a finance afterthought, are routinely reducing AI spend by 30–60% without meaningful performance degradation. Here's how.
Why AI Costs Are Different (and Harder to Control)
Before jumping to tactics, it's worth understanding why AI costs behave differently from traditional infrastructure.
They don't rise linearly. Unlike compute or storage, AI costs jump, compound, and cascade through a system in unpredictable ways. A poorly structured prompt, a misconfigured agent, or an inefficient retrieval pipeline can quietly multiply costs across every user request.
Ownership is diffuse. AI responsibility typically sits across ML engineering, platform teams, product, and finance, with no single owner accountable for the full lifecycle cost. Waste accumulates at every handoff.
Visibility is poor. Unlike cloud compute, where you can map spend to instances and services, AI cost attribution is harder. Token-based billing, variable GPU utilization, and opaque model pricing make it genuinely difficult to answer: which feature, workflow, or team is driving this cost?
Agentic systems introduce new risk. A single AI agent caught in a recursive loop can rack up thousands of dollars in a single afternoon. As agentic architectures become common, unguarded inference loops are becoming one of the most significant new sources of runaway spend.
Understanding this shapes what optimization actually looks like in practice.
1. Before You Optimize AI Costs, Start with Visibility
You cannot optimize what you cannot see. This sounds obvious, but most organizations skip straight to tactics (switching models, compressing prompts) without first establishing the observability foundation that makes those tactics measurable.
What to instrument:
- Cost per query / per request - broken down by feature, use case, or team
- Tokens per request - both input and output, tracked over time
- Cache hit rates - how often are you paying for work you've already done?
- Model usage distribution - which models are serving which requests?
- Failure and retry rates - retries quietly double or triple inference costs
The goal is to build unit economics for AI: cost per outcome, not just a total bill. Many teams discover that their most expensive queries aren't their most complex ones. They're the result of poorly structured prompts or inefficient workflows that no one has revisited since the prototype stage.
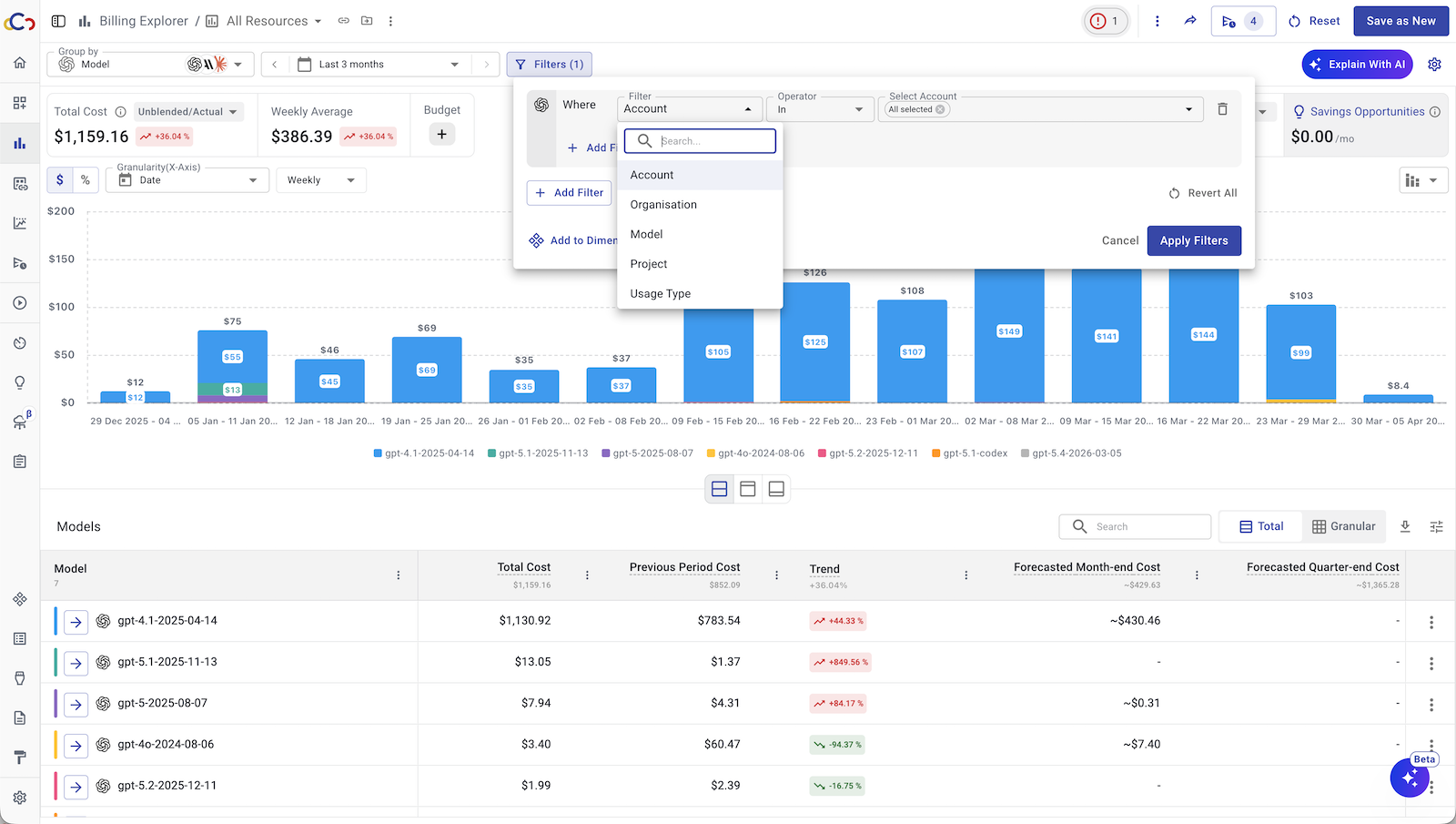
This is one of the core problems Cloudchipr was built to solve. Rather than forcing teams to build their own cost telemetry from scratch, Cloudchipr provides automatic insights on cost changes, spikes, and trends across your full cloud and AI infrastructure, without manual analysis. You get full visibility of your OpenAi and Anthropic costs, cloud providers, Kubernetes, and 30+ other sources. Its conversational AI interface lets engineers and FinOps practitioners ask plain-language questions like "why did our costs spike last week?" and receive instant, context-rich explanations along with generated charts and reports. For multi-cloud environments, it consolidates everything into a single pane, so cost attribution doesn't require stitching together separate billing consoles.
Assign ownership. Visibility data is only useful if someone is accountable for acting on it. The most effective teams designate an AI FinOps champion, someone embedded in engineering who speaks both cost and architecture, rather than leaving it as a shared responsibility that falls through the cracks.
2. Right-Size Your Models with Intelligent Routing
One of the highest-leverage tactics available today is also one of the most underused: model routing.
Most AI workloads follow a clear pattern. A small fraction of requests require deep reasoning - complex synthesis, nuanced judgment calls, multi-step analysis. The majority are simpler tasks: classification, extraction, summarization, short-form Q&A, and routing decisions. Yet many organizations default every request to their most capable (and most expensive) model, because it's the easiest configuration to start with, and no one has gone back to revisit it.
A model routing layer evaluates each request by complexity, intent, or confidence threshold and directs it to the appropriate model. Routine traffic goes to lighter, cheaper models. Heavyweight tasks trigger your frontier model selectively. Done well, this approach can reduce inference costs by 30–50% while maintaining output quality at the application level.
Practical starting point: Audit your top 10 highest-volume use cases. For each, ask honestly: does this task require GPT-4-level reasoning, or would a smaller, faster model handle it well? The answer for most will surprise you.
3. Treat Prompt Engineering as a Cost Discipline
Prompt design affects cost as much as infrastructure choices - arguably more, because it's something every engineer and product team can influence immediately.
The core problem: long system messages, repeated context, unnecessary verbosity in outputs, and unstructured instructions inflate token usage silently on every request. When multiplied across millions of daily calls, the cost impact is substantial.
Key practices:
- Trim system prompts aggressively. Every unnecessary sentence in a system prompt is paid for on every call. Audit prompts quarterly as a standing practice, not a one-time cleanup.
- Constrain output length. If your use case needs a three-sentence answer, tell the model. Unconstrained output instructions are one of the most common sources of token waste.
- Structure inputs. Unstructured, rambling inputs force the model to do more work. Clear, structured prompts consistently reduce token count and improve response quality simultaneously.
- Place static content strategically. Most providers support prompt caching. Place static elements (system instructions, policy documents, knowledge base content) at the top of your prompts to maximize cache eligibility. The savings are significant: caching the same 50,000-token document across 20 questions eliminates nearly a million redundant token processings.
A disciplined prompt optimization practice typically yields 15–40% cost reduction as a baseline, and it compounds over time as prompts are continuously refined.
4. Fix Your RAG Layer
Retrieval-Augmented Generation (RAG) entered the industry as a solution for grounding model responses in real data. Poorly engineered, it often becomes one of the biggest sources of waste in an AI stack.
The core issue: native RAG implementations stuff large amounts of retrieved content into the context window regardless of relevance. For many production systems, 70–80% of the tokens being sent to the model are unnecessary - retrieved passages that don't materially contribute to the response. You're paying for context that the model either ignores or downweights.
What good RAG engineering looks like:
- Chunking strategy matters. Larger chunks are not always better. Thoughtful chunk sizing aligned to your query patterns reduces both retrieval noise and context length.
- Hybrid search. Combining semantic (vector) search with keyword search significantly improves retrieval precision, meaning you pull fewer, more relevant chunks.
- Metadata filtering. Use metadata to pre-filter the retrieval space before semantic search. This reduces both retrieval cost and the volume of irrelevant content making it into the context.
- Re-ranking. A lightweight re-ranker model can dramatically improve the quality of what you send to your frontier model, often paying for itself many times over by reducing the amount of context needed.
Treating retrieval engineering as a core competency, not an infrastructure detail, is one of the clearest differentiators between organizations that scale AI economically and those that don't.
5. Use Async Processing Where You Can
Real-time inference is expensive. Not every AI workflow needs it.
Evaluate each use case for its actual latency requirement. Internal analytics, reporting pipelines, risk scoring, document enrichment, and batch classification tasks rarely require sub-second responses, yet they are often routed through the same real-time inference path as user-facing features, because that's how the system was initially built.
Moving appropriate workloads to asynchronous, batch-processed pipelines unlocks several cost levers:
- Batch API pricing - most providers offer meaningful discounts (often 50% or more) for async batch inference
- Scheduling control - run batch jobs during off-peak hours to take advantage of lower spot compute pricing
- Retries without penalty - async jobs handle failures more gracefully without user-visible impact
A practical rule of thumb: if no human is waiting on the response in real time, it's a candidate for async.
6. Build Cost Guardrails Into Your Architecture
Optimization practices are only sustainable if they're structurally enforced, not reliant on individual engineers remembering to be cost-conscious.
This means embedding cost guardrails at the architecture level:
- Hard caps on agent reasoning loops. For agentic systems, define maximum iteration counts and reasoning steps. A single agent without a ceiling can run indefinitely and generate catastrophic costs.
- Spend alerts and auto-shutoffs. Configure real-time alerts at the API and infrastructure level. An agent that goes rogue at 2 AM should trigger an automatic kill, not a morning Slack message.
- Token budgets per request type. Establish maximum token budgets for each use case class and enforce them at the API layer. This prevents gradual prompt bloat from silently inflating costs over time.
- Pre-deployment cost estimation. Before launching a new AI feature or workflow, estimate its cost at the target scale. The FinOps community calls this "shift-left costing," and it's one of the top practitioner requests in 2026.
Cloudchipr directly supports this layer of the stack. Its automated workflows continuously scan your infrastructure for idle or underutilized resources and take action - cleaning up orphaned resources, enforcing tagging policies, scheduling resources to shut down during off-hours, without requiring manual intervention. Anomaly detection with AI-generated explanations means your team gets notified the moment costs deviate from expected patterns, with enough context to act immediately rather than investigate. Customers report saving an average of $180,000 per month and reclaiming around 200 engineering hours previously spent on manual cost management tasks.
7. Make AI Cost a Cross-Functional Practice
The teams that manage AI costs most effectively have one thing in common: they've made it a shared practice, not a siloed function.
Engineering owns the architecture. FinOps owns the visibility and accountability framework. Product owns the use-case ROI. AI/ML leads own model selection and prompt standards. When these functions operate independently, costs accumulate at the seams - in handoffs, in duplicated infrastructure, in features that were never evaluated for their cost-to-value ratio.
The FinOps Foundation's 2026 data reflects this shift: 78% of FinOps teams now report into the CTO or CIO organization (up from 61% in 2023), signaling that cost management is increasingly viewed as a technology and architecture capability, not just a finance reporting function. Teams with this executive alignment report two to four times more influence over technology selection decisions.
This is where a platform like Cloudchipr becomes infrastructure in its own right. Rather than engineering teams building one set of dashboards and FinOps teams maintaining another, Cloudchipr is designed to speak the language of all three audiences - engineering, finance, and leadership, from a single platform. Engineers get live resource views and automated remediation workflows. FinOps practitioners get allocation, anomaly detection, and forecasting. Leadership gets consolidated visibility across all cloud providers in one place. That shared context is what makes cross-functional AI cost ownership operationally real, rather than just an org-chart intention.
Practically, this also means:
- Establishing a regular AI cost review as a standing ritual (monthly or per sprint)
- Tying AI feature launches to projected unit economics, not just technical feasibility
- Celebrating efficiency improvements the way you celebrate feature launches
Where to Start
If you're reading this with an AI bill that feels out of control, here is a prioritized sequence for AI cost optimization:
- Instrument first. You need unit-level cost visibility before any other step is meaningful. If you don't have that infrastructure, Cloudchipr can get you there quickly across AWS, GCP, and Azure without building bespoke tooling.
- Audit your top 10 workflows. For each, evaluate: right model? Right prompt length? Real-time or async? This single exercise typically surfaces 20–40% savings opportunities.
- Add caching. Prompt caching is one of the highest-ROI, lowest-risk changes you can make. If you haven't enabled it, do it immediately.
- Build guardrails for agents. If you're running any agentic workflows, add hard limits on iteration and real-time spend alerts before they become a problem.
- Establish ownership. Assign a person or small team to be accountable for AI cost. Without ownership, insights don't become action.
AI cost optimization isn't a one-time project. It's an ongoing engineering discipline - one that compounds over time as your systems become leaner, your prompts become tighter, and your team develops cost intuition the way it's developed performance intuition. The organizations building that muscle now will carry a durable advantage as AI scales become even larger.
The bill is due. The good news is, the tools to pay it efficiently are right in front of you.


