Pre-Deployment AI Cost Review: A Practical Guide for Engineering Teams

Introduction
The AI bill arrives weeks after the decisions that drove it. By the time your finance team flags the number, you have already committed to a model, a deployment pattern, a context window strategy, and an inference volume assumption that is genuinely painful to unwind. You are not optimising at that point. You are remediating.
This is the AI cost problem in a sentence: the decisions that determine 80% of your spend happen at the design stage, but cost review happens after deployment. Pre-deployment architecture costing closes that gap. It is the #1 desired new tooling capability in the 2026 FinOps survey, and yet most engineering teams still treat cost as a post-deployment concern, something to fix once the bill is visible rather than something to design around before the first line of infrastructure is written.
The parallel to shift-left security is exact: cost gates belong in the design review, not the post-deployment retrospective. A complete architecture proposal in 2026 should include not just availability zones and compute sizing, but an egress cost model, a storage tier decision matrix, and a GPU placement rationale if AI workloads are involved. This article is the how-to that the trend pieces do not provide.
Why AI Makes Pre-Deployment Costing Urgent and Hard
This is not just standard FinOps best practice applied to a new workload type. AI architectures have specific characteristics that make late-stage cost discovery uniquely painful, and that make the usual post-deployment remediation toolkit much less effective.
Cost is embedded in design decisions, not just resource choices. Choosing GPT-4o over Claude Haiku is not a procurement decision. It is an architecture decision made at the feature spec level. By the time it reaches a design review, it already has momentum. Reversing a model selection mid-build is expensive; reversing it post-launch is nearly impossible without user-facing changes.
Token consumption is non-linear and hard to estimate from the outside. A poorly scoped context window, an underspecified output length, or an unguarded agent loop can produce 10x the expected token spend under real user behaviour. Traditional capacity planning models were not built for this kind of variability. A workload that costs $200/month in testing can cost $8,000/month at production traffic, not because traffic scaled 40x, but because real users write longer messages, trigger longer outputs, and hit edge cases your test suite did not cover.
The gap between experiment and production cost is enormous. Experimental AI workloads and production inference have completely different cost profiles, failure modes, and governance needs. Most cost surprises happen when a proof-of-concept pattern gets promoted to production without any cost architecture review. The team that built the prototype is proud of what it does, and nobody asks what it costs to do it at scale.
The result is that engineering teams end up reactive by default, not because they do not care about cost, but because the process does not create a natural moment to confront it before commitments are made.
The Four Architectural Decisions That Determine 80% of AI Cost
Before process or tooling, you need to be clear on what actually needs to be costed at design time. Four decisions account for the overwhelming majority of AI spend at production scale. If your design review addresses these four explicitly, with cost estimates attached, you will catch the problems that matter.
1. Model Selection and Tiering Strategy
This is the single highest-leverage cost decision in any AI architecture. The choice of model, and whether a tiering or routing strategy is defined, should be made explicitly at design time with cost estimates attached, not left to individual engineers to resolve at implementation.
In practice, this means documenting which model handles which task type, what the fallback chain is, and what the estimated cost differential is between tiers. A customer support flow that routes simple intent classification to a smaller model and escalates complex reasoning to a frontier model might cost 60 to 70% less than an architecture that uses the frontier model for everything, and that decision is trivially available at design time.
2. Context Window and Prompt Structure
Context window size is a direct cost multiplier, and it is almost never treated as a cost constraint at design time. A system prompt that grows from 500 to 2,000 tokens, because nobody pushed back on what got included, doubles the input cost of every request. At scale, that is not a rounding error.
At design time, define the maximum context length per request type, system prompt size with a documented rationale for every section, and the token budget per request. These are not hard constraints that require finance approval. They are engineering decisions that should be made explicitly rather than left to accumulate by default.
3. Inference Pattern: Real-Time vs. Batch vs. Async
The decision to process requests synchronously versus asynchronously has a direct cost implication that is almost always available at design time but rarely made explicitly. Batch API pricing from major providers typically runs at 50% of real-time pricing, a straightforward 2x cost saving for workloads that do not require sub-second response.
The question to ask at design review: does this workload actually require real-time response, or does it require eventual response within an acceptable window? Document generation, report summarisation, nightly data enrichment, these are batch workloads that frequently get implemented as real-time calls because nobody asked the question. Any workload that does not require sub-second response should default to async batch unless there is a documented reason otherwise.
4. Caching and Retrieval Architecture
Prompt caching, semantic caching, and RAG retrieval depth all reduce token consumption at runtime, but only if they are designed in from the start. Retrofitting a caching layer into a production AI system is expensive and disruptive. The architecture decision needs to happen before the system is built, not after the first bill arrives.
At design time: specify whether prompt caching will be used for static system prompt content, define the expected cache hit rate assumption, and document the retrieval chunk strategy and depth limits for any RAG components. A RAG system that retrieves 20 chunks per query costs substantially more to operate than one that retrieves 5, and the quality difference is often marginal.
The principle underlying all four decisions is the same: each has a cost range that can be modelled at design time with reasonable accuracy. The goal is not precision. It is establishing a cost envelope before commitments are made.
What a Pre-Deployment Cost Review Actually Looks Like
This does not need to be a heavyweight governance process. The missing piece is not ambition. FinOps teams are already engaging with Platform Engineering and Enterprise Architecture, building pricing calculators and offering pre-deployment guidance. What is missing is a standard format that makes cost a natural part of the engineering design process rather than a separate finance concern.
The simplest version is a five-field cost estimation template that lives in the design doc alongside latency targets and reliability requirements:
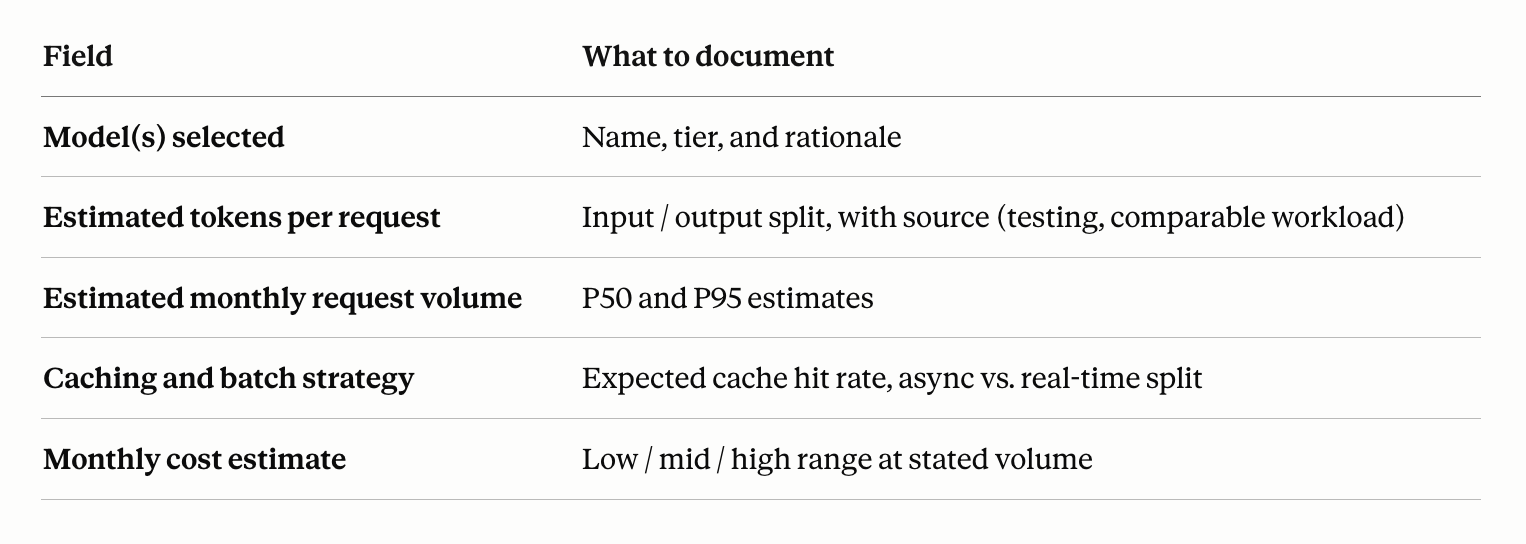
This is an engineering artifact, not a finance deliverable. The goal is to surface cost assumptions explicitly so they can be challenged, not to produce an accountant-grade forecast.
Where it fits in the lifecycle:
- At RFC / design doc stage: complete the cost estimation template as part of the proposal. No approval needed, just visibility.
- At design review: cost estimate reviewed alongside performance and reliability assumptions. Flag if the mid-case estimate exceeds a defined threshold for a new feature.
- At production launch: actual cost in the first 30 days compared against the estimate. Variance feeds back into future estimation quality.
The last step is the one most teams skip, and it is the most important one. The estimate-to-actual comparison is not an accountability mechanism. It is a calibration mechanism. Teams that track estimate accuracy improve faster.
This is also where tooling starts to earn its place. Cloudchipr's Billing Explorer and per-workload cost visibility give teams a concrete way to pull that 30-day actual figure, broken down by service, feature, and environment, without manually stitching together data from multiple provider consoles. The estimate lives in the design doc; the actual lands in the dashboard. Closing that loop is what turns a one-time cost review into an improving feedback system.
How to Produce Numbers Before You Have Data
The most common objection to pre-deployment costing is that you cannot estimate token costs accurately before you have built anything. That is partly true and largely irrelevant. You do not need precision; you need a defensible range. Here are three methods that get you there.
Method 1: Workload archetype benchmarks. Use published benchmarks and workload archetypes as a starting point. A customer support chatbot might average around 800 input tokens and 300 output tokens per conversation; a document summarisation pipeline might average around 3,000 input and 400 output. An engineer designing a new workload can use the closest archetype as a baseline and adjust for their specific system prompt size and expected response length. This approach typically gets you within 2 to 3x of actual production cost, accurate enough for a go/no-go threshold check, which is all the design review needs.
Method 2: Prototype sampling. Before the production design is finalised, run 50 to 100 representative requests through the target model and measure actual token consumption. This is a $5 to $20 investment that produces far more accurate estimates than any spreadsheet model. Document the sampling methodology and the inputs used so the estimate is auditable when the production number comes in.
Method 3: Comparable workload reference. For teams with existing AI workloads in production, use cost-per-request data from similar workloads as a reference baseline. This requires that existing workloads are instrumented to produce per-request cost data, which most are not yet. Instrumenting them creates a reference library that makes future estimates progressively more accurate.
This is one of the more practical ways Cloudchipr adds value early in the process. By tagging AI workloads with Dimensions, Cloudchipr's dynamic cost grouping layer, teams can generate per-feature and per-request cost data from existing production workloads without changing their cloud provider tagging structure. That data becomes the reference library that makes every subsequent pre-deployment estimate sharper. Teams that instrument their first AI workload properly are typically estimating their third and fourth ones with far greater confidence.
The honest caveat: pre-deployment estimates will be wrong. The goal is to be wrong in a bounded, documented way so that when the production number arrives, the team knows whether the variance is expected or signals a design problem that needs to be addressed.
Getting Engineering to Own Cost at Design Time
The process is only half the problem. The other half is organisational: engineers need to see cost estimation as part of their job, not a finance imposition. The friction point is not technical. It is that cost prevention is invisible. Once you prevent waste upstream, it disappears from downstream reporting. Nobody files a ticket for the problem that did not happen.
Three things that move the needle:
Make cost estimates a first-class part of the design doc, not an appendix. When cost sits alongside latency targets and SLO definitions, it signals that it is a design constraint, not a finance check. Engineers respond to constraints they helped define. An estimated monthly cost on page one of a design doc changes the conversation in a way that a separate FinOps review two weeks later never will.
Create a feedback loop between estimates and actuals. The 30-day post-launch review that compares estimated versus actual cost is more valuable as a learning mechanism than as an accountability mechanism. Frame it as calibration rather than audit. Cloudchipr's anomaly detection with AI-generated explanations plays a specific role here: when the actual figure deviates from the estimate, the platform surfaces why, identifying which service, which request type, and which usage pattern drove the variance. This gives teams the diagnostic context they need to improve future estimates rather than just react to the current bill. Teams that understand their cost variances get better at predicting them.
Celebrate avoided cost, not just reduced cost. The FinOps teams doing this well are the ones treating pre-deployment interventions as wins, with the same recognition that post-deployment savings get. If the only visible wins are reactive, the incentive is always to be reactive. An engineer who catches a 10x cost problem at design review prevented exactly the same dollar value as an engineer who reduced production spend by the same amount. Making that visible through dashboards that track estimated-versus-actual savings, or budget alerts that never fired because the design was sound, is the kind of recognition loop that changes engineering culture over time.
Cloudchipr's Budgets and Alerts feature supports this directly: teams can set per-workload budget thresholds tied to their pre-deployment estimates and receive proactive alerts through Slack, Teams, or Jira if actual spend approaches or exceeds the projected range. The alert becoming an absence of alert, because the estimate was accurate and the design was sound, is itself a signal worth tracking.
The Compounding Advantage
Organizations that adopt shift-left cost practices are not just reducing their AI bills. They are building institutional knowledge that compounds over time.
The estimate-to-actual feedback loop, accumulated across dozens of features and workloads, eventually becomes a competitive advantage. Teams that can accurately forecast AI costs can propose more ambitious AI initiatives with confidence and defend them to leadership with data. Teams that cannot are always explaining why the last bill was higher than expected, which is not a position from which anyone approves ambitious new investments.
The winning approach is developer-native: instrumentation that fits the way teams already ship software, and cost gates that run in the design process alongside performance and reliability review, not as a retrospective after the invoice. Cloudchipr is built around exactly this philosophy. Anomaly detection and per-workload cost visibility feed the upstream design decisions that generated the costs in the first place, creating a closed loop between the estimates engineers write and the actuals they are accountable for.
For teams starting this journey, the sequence is straightforward: instrument your existing AI workloads to generate per-request cost data, use that data to build your first workload archetypes, apply those archetypes at the next design review, and close the loop at 30 days post-launch. The tooling is available. The process is lightweight. The compounding starts on the first cycle.
The architectural decisions are being made anyway. The only question is whether cost is in the room when they are made.


