How an Enterprise AI Learning Platform Reached 99.99% Uptime and Cut Cloud Costs ~60% (CNCF Case Study)

An enterprise AI-powered learning platform outgrew its managed PaaS. As adoption grew, releases became riskier, peak-time incidents increased, and costs spiked with limited attribution. Cloudchipr partnered with the team to rebuild on a standards-based, vendor-neutral stack—Kubernetes on AWS with GitOps, modern autoscaling, and FinOps automation. The result: 99.99% availability and ~60% lower cloud spend, delivered with no user-visible downtime.
The Starting Point: Reliability and Cost Gaps
The platform’s PaaS footprint hid too much operational detail. Rollbacks were slow, scaling was coarse, and observability was fragmented. Costs were volatile and difficult to allocate because of inconsistent tagging and idle resources lingering across environments. Leadership wanted strict SLAs and unit-economics clarity (e.g., cost per active learner). The requirement was straightforward but demanding: move to a resilient, measurable, and auditable operating model—without interrupting customer experience.
Architecture and Delivery Model
The migration centered on AWS EKS with private networking and multi-AZ worker nodes. Stateless services run behind an ingress controller and scale horizontally; asynchronous workers handle queues and scheduled jobs; stateful needs are satisfied by a mix of managed data services and selective StatefulSets. Reliability is protected via rolling and blue-green updates, PodDisruptionBudgets (PDBs), anti-affinity rules, automated backups, and documented RPO/RTO targets aligned with SLOs.
Delivery shifted to a GitOps model using Argo CD and Helm. Git is the single source of truth; Argo CD continuously detects drift, evaluates app health, and syncs changes automatically or on demand. An app-of-apps pattern promotes releases through environments with auditable histories. Helm charts and per-environment values keep deployments consistent while enabling fast, clean rollbacks.
Autoscaling Without Waste
The platform combines three complementary layers of elasticity:
- HPA for service responsiveness. Horizontal Pod Autoscaler scales pods based on CPU, memory, or custom metrics for steady-state demand.
- KEDA for event bursts. KEDA reacts to external signals—queue depth, stream lag, HTTP throughput—so workers scale out quickly during spikes and back to zero when idle.
- Karpenter for infrastructure efficiency. Karpenter provisions nodes on demand and consolidates under-utilized capacity, supporting both On-Demand and Spot while honoring PDBs and topology constraints. This reduces waste materially without sacrificing reliability.
Together, these layers allowed the team to scale-test beyond 200 Kubernetes nodes and keep costs proportional to load, rather than provisioned headroom.
Observability Built for SLOs and Retention
Prometheus, Loki, and Grafana form the observability stack. Prometheus scrapes application and cluster metrics, then uses remote-write to store time series durably in Amazon S3—separating retention economics from cluster storage. Loki centralizes logs in S3 as well, simplifying capacity planning. Grafana provides unified dashboards across performance, reliability, and business KPIs, plus alerting tied to SLOs. Engineers get clear, correlated signals; finance and leadership get dependable, long-horizon views.
FinOps and Policy Enforcement
With Cloudchipr’s FinOps platform, the company gained consolidated visibility across providers, consistent tagging, and allocation by team/service. That foundation enabled:
- Accurate unit economics. Costs mapped to services and environments, answering “what does it cost per active learner?”
- Automation for hygiene. Safe policies remove unattached LBs/volumes/EIPs and expire preview environments, preventing silent spend.
- Anomaly detection and guardrails. Finance and engineering collaborate with shared data and budgets enforced in tooling, not meetings.
This sequence—allocate first, then optimize workloads, then tackle rate optimization—kept improvements compounding and auditable.
Outcomes and Why It Matters
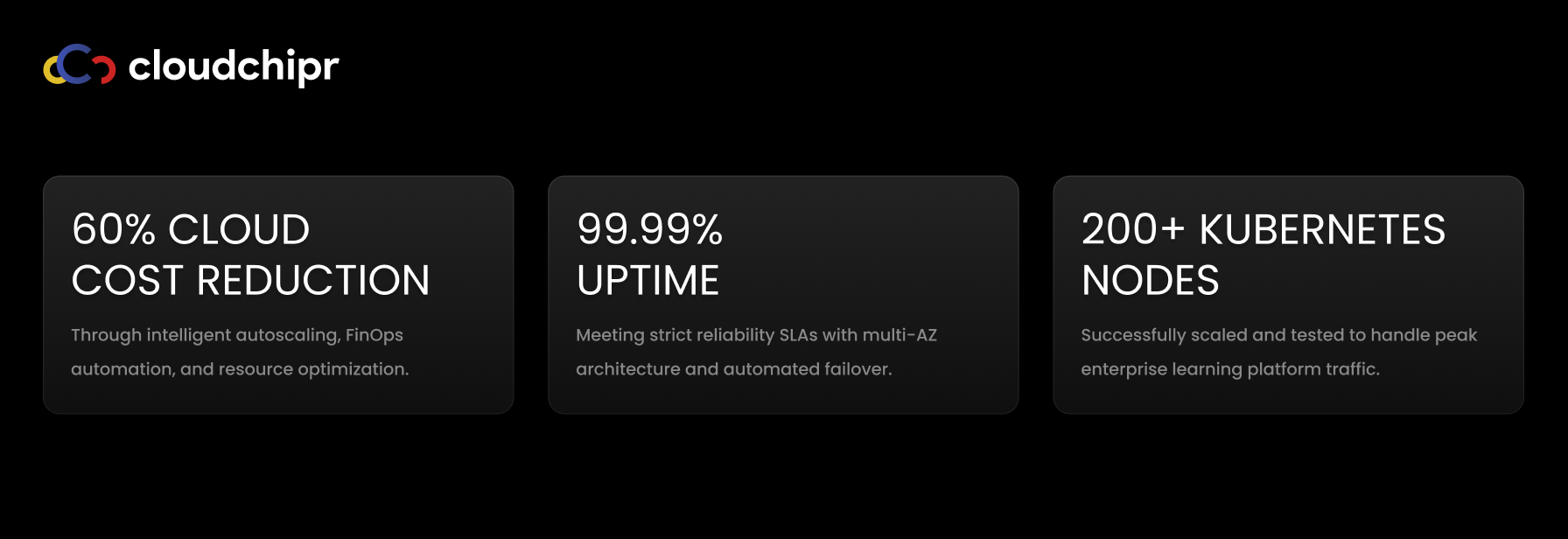
- ~60% cost reduction. Waste was removed at the workload and node layers; reserved/spot strategies landed on a clean allocation baseline.
- 99.99% uptime. Multi-AZ architecture, PDBs/anti-affinity, blue-green updates, and fast, Git-backed rollbacks protected availability.
- Faster, safer releases. Drift detection, health checks, and app-of-apps promotion standardized delivery.
- Scale confidence. Successful tests past 200 nodes demonstrate headroom for future growth.
For organizations moving off opinionated PaaS platforms, this case shows a pragmatic path: pair Kubernetes and GitOps with targeted autoscaling, durable observability, and cost policy. The payoff is reliability you can measure and costs you can explain—without locking into a single vendor’s abstractions.
See the complete implementation in the CNCF case study
Meet us at KubeCon + CloudNativeCon North America 2025
Booth #2141, November 10–13.

Working on similar Kubernetes/GitOps + FinOps challenges? Stop by and say hi.


