Demystifying Google Cloud Dataproc in 2025: The Practical Guide
.png)
Introduction
Google Cloud Dataproc (often shortened to Dataproc or GCP Dataproc) has matured from a niche managed service to a foundational element of modern data platforms. As organizations increasingly embrace cloud‑native analytics, this fully managed Apache Spark and Hadoop service continues to simplify distributed computing while offering the flexibility to process data where it lives. This article takes a candid look at Dataproc’s architecture, features, pricing, and how it stacks up against alternatives such as Dataflow and Databricks. Whether you’re migrating on‑premises Hadoop workloads, building data lakes on Google Cloud, or evaluating the broader analytic landscape, this deep dive aims to give you the strategic clarity you need.
Why Dataproc?
Before diving into technical specifics, it helps to understand what Dataproc is and why it exists. At its core, Dataproc is Google Cloud’s fully managed service for running open‑source data processing frameworks like Apache Spark, Hadoop, Flink and Presto. This managed approach eliminates the heavy lifting of manual cluster provisioning, configuration and monitoring. Dataproc automatically configures clusters, scales resources and keeps them up to date with new Spark and Hadoop releases while integrating with other GCP products such as BigQuery and Vertex AI. It also decouples storage from compute by storing data in Google Cloud Storage (GCS) rather than local HDFS, allowing clusters to be spun up and shut down without data loss—a key advantage over traditional on‑premise Hadoop clusters.
This managed design addresses long‑standing pain points in the Hadoop ecosystem: the operational complexity of installing and tuning clusters, the inflexibility of on‑prem hardware, and the cost of maintaining idle nodes. GCP Dataproc’s pay‑as‑you‑go model and per‑second billing provide cost efficiency, while its seamless integration with other GCP services enables end‑to‑end analytic pipelines.
Architectural Deep Dive
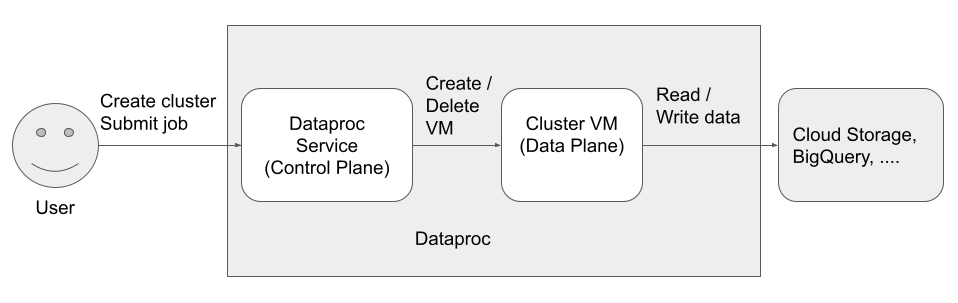
Understanding Dataproc’s architecture clarifies how the service achieves both flexibility and efficiency. Dataproc provisions clusters quickly (often in under 90 seconds) and runs on Compute Engine VMs. The architecture decouples compute from storage and integrates with various GCP services.
Cluster Components
A Dataproc cluster comprises three primary node types:
- Master node: This acts as the control plane for the cluster. It runs the Spark driver or the YARN ResourceManager, along with the HDFS NameNode and Job History servers. High‑availability configurations support multiple masters to avoid single points of failure.
- Worker nodes: These are the workhorses. Each worker runs NodeManager (if using YARN), HDFS DataNode and Spark executors. Workers handle data processing tasks and can scale up or down manually or via autoscaling.
- Secondary workers (preemptible VMs): For cost optimization, clusters can include preemptible worker nodes. These short‑lived VMs offer lower pricing but may be terminated at any time; Dataproc transparently reassigns tasks when this happens.
All nodes are Compute Engine VMs and can be customized in CPU, memory and disk configurations. By abstracting this complexity away, Dataproc lets data engineers focus on code rather than infrastructure.
Control Plane and Workflow Management
Cluster lifecycle management is central to the Dataproc experience. Users can create, resize and delete clusters through the Cloud Console, the gcloud CLI or REST APIs. Autoscaling policies dynamically adjust worker count based on workload demand, and preemptible VMs can be included to further reduce costs. The ability to define initialization actions during cluster creation allows fine‑tuning of packages and configurations.
Dataproc’s security architecture is also robust. Clusters operate within a Virtual Private Cloud (VPC), enabling network isolation, and support Private Google Access, TLS/SSL encryption and IAM role‑based access control. Logs and metrics are exported to Google Cloud’s operations suite for monitoring.
Storage and Data Flow
A design principle that sets Dataproc apart from legacy Hadoop clusters is the decoupling of persistent storage from compute. Instead of relying on HDFS, Dataproc uses Google Cloud Storage (GCS) as the primary data lake. Data can be ingested from sources like Pub/Sub and then processed within the cluster before being stored back into GCS or integrated with analytics services like BigQuery or Bigtable. This architecture allows clusters to be ephemeral—they can be created on demand for specific jobs and deleted afterward, saving costs and improving agility.
Cluster Management, Autoscaling and Serverless
Autoscaling
One of the most compelling features of Dataproc is autoscaling, which automatically adjusts cluster size based on workload needs. Autoscaling works by comparing pending memory (memory requested by running jobs) with available memory; the cluster scales up if the pending memory exceeds the available memory and scales down when there is unused capacity. Autoscaling parameters include:
- scaleUpFactor and scaleDownFactor: control how aggressively the cluster scales in or out.
- cooldownPeriod: sets a waiting time between scaling actions to prevent oscillation.
Autoscaling is ideal for workloads with variable resource requirements. Autoscaling currently doesn’t support Spark Structured Streaming and cannot scale to zero, meaning at least one node remains active.
Serverless Dataproc
While autoscaling allows you to add or remove VMs dynamically, Dataproc Serverless goes further by abstracting away cluster management entirely. Dataproc Serverless as allowing users to run Spark workloads without provisioning clusters. You submit a batch job (e.g., via the gcloud CLI or API), and the service spins up a serverless environment to execute the job. Once the job completes, resources are reclaimed automatically.
Serverless Spark is especially useful for infrequent or unpredictable workloads because it eliminates the need to provision and maintain clusters. Pricing is consumption‑based, which we explore later, and there is no overhead from idle VMs. The trade‑off is less control over node customization and slower startup times compared to long‑running clusters.
Dataproc vs Dataflow: When to Use Which?
.png)
Google Cloud offers multiple data processing services, and choosing between Dataproc and Dataflow can be confusing.
Dataproc is ideal for running Spark and Hadoop workloads with minimal operational overhead. It offers managed open‑source software, resizable clusters, autoscaling, and the ability to delete clusters when not needed. Dataproc excels when you need direct access to the Spark APIs, custom libraries and control over cluster configuration. It is also a natural fit for migrations from on‑prem Hadoop or hybrid cloud setups.
Dataflow, by contrast, is a fully managed stream and batch processing service based on Apache Beam. Its strengths include automatic scaling, dynamic work rebalancing and seamless integration with data ingestion services. Dataflow is designed for event‑driven pipelines and complex data transformations. Because Dataflow hides the execution engine behind Beam abstractions, it’s better suited for continuous streaming pipelines or unified batch/stream processing tasks. Pricing for Dataflow is also consumption‑based.
When to choose one over the other?
- Choose Dataproc if you need to run existing Spark, Hadoop, or Hive scripts with minimal code changes, require interactive job submission, or want to manage cluster configurations and memory allocation yourself.
- Choose Dataflow if you are building new pipelines using Apache Beam that require autoscaling and dynamic load balancing, especially for streaming analytics or ETL workloads that need robust windowing and state management.
Pricing Models: How Much Will Dataproc Cost?
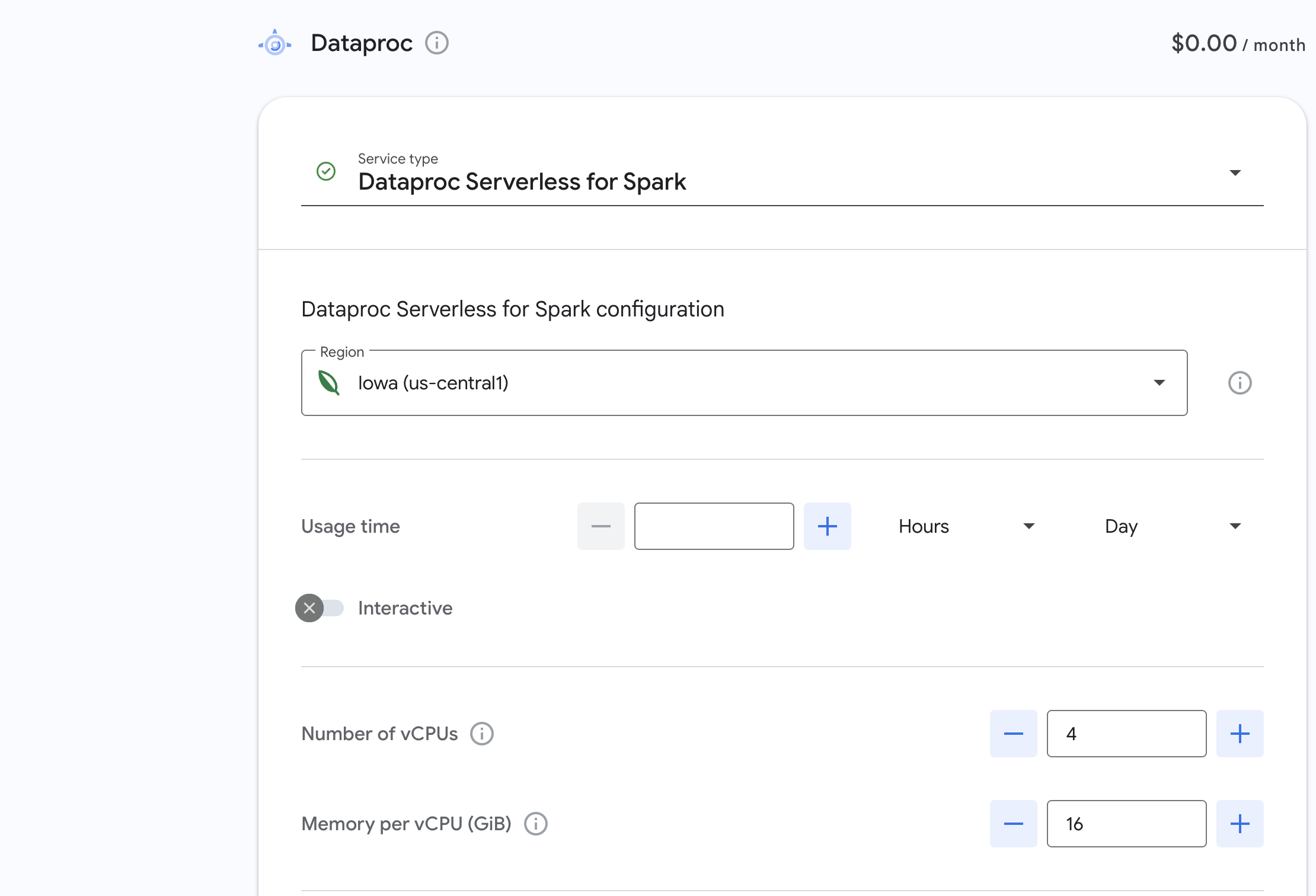
Standard Dataproc on Compute Engine
For traditional clusters running on Compute Engine, Dataproc pricing is based on the total number of vCPUs and the duration the cluster is running. The base formula is simple:
Cost = $0.01 × (# of vCPUs) × (hours of runtime)
Billing is per second with a minimum of one minute, and the “size” of a cluster equals the aggregate vCPUs across master and worker nodes. Additional charges apply for Compute Engine VMs, persistent disks, network traffic and monitoring. Costs accrue from the moment nodes are active until they are removed, including periods when the cluster is resizing.
Example: a 24‑vCPU cluster running for two hours would cost 24 × 2 × $0.01 = $0.48 (not including underlying compute, storage or network charges).
Dataproc on GKE
Running Dataproc on Kubernetes Engine uses the same pricing formula but charges apply to vCPUs in Dataproc‑created node pools. Billing remains per second with a one‑minute minimum. Additional GKE management fees apply, and node pools may persist after cluster deletion unless explicitly scaled to zero.
Dataproc Serverless Pricing
Serverless Spark shifts the pricing model to consumption metrics rather than provisioned vCPUs. Chaos Genius outlines the components:
- Data Compute Units (DCUs): unify vCPU and memory usage. Each vCPU equates to 0.6 DCUs and memory contributes 0.1 DCU per GB up to 8 GB, then 0.2 DCU per GB above that . DCUs are billed per second with a minimum of one minute.
- Shuffle storage: intermediate data written during Spark shuffles is billed per GB per month with a minimum usage window (1 minute for standard, 5 minutes for premium).
- Accelerators: optional GPUs or other hardware (e.g., NVIDIA A100 or L4) are charged separately with a minimum 5‑minute charge.
Default serverless workloads allocate 4 vCPUs and 16 GB for the driver (4 DCUs) and two executors with the same configuration (8 DCUs total), resulting in a baseline of 12 DCUs per job. Additional charges apply for storage, network traffic and monitoring.
Databricks Pricing for Comparison
Because many organizations evaluate Dataproc against Databricks, it’s useful to compare pricing models. Databricks uses a consumption‑based model centered on the Databricks Unit (DBU). A DBU aggregates CPU, memory and I/O resources consumed per hour. The total cost equals DBUs consumed multiplied by the DBU rate, which varies by cloud provider, region and service tier. Databricks provides free trials and a Community Edition for learning. This DBU‑based model may result in more complex cost estimation but offers fine‑grained control over consumption.
Dataproc vs Databricks
.png)
Architectural Differences
- Dataproc architecture focuses on quickly provisioning clusters on Compute Engine, decoupling compute from storage via GCS and integrating with GCP services like BigQuery, Pub/Sub and Vertex AI. Users can customize VM types, specify initialization scripts and leverage preemptible nodes for cost savings.
- Databricks architecture builds on an optimized Spark runtime and the Photon execution engine. It introduces the Delta Lake format with ACID transactions and time travel, enabling a unified lakehouse architecture. Databricks also provides a collaborative workspace with notebooks, MLflow integration and performance enhancements through the Photon engine.
Data Processing and Ecosystem Integration
Dataproc supports more than 30 open‑source tools and frameworks, including Spark, Hadoop, Hive and Flink. It integrates tightly with GCP services, decouples storage via GCS and allows full customization of clusters, making it ideal for data lake modernization, ETL and secure data science. Dataproc also supports Apache Spark Structured Streaming, enabling unified streaming and batch workloads.
Databricks, meanwhile, extends Spark with the Databricks Runtime and Photon engine for significant performance gains. Its built‑in Delta Lake layer adds ACID transactions, schema enforcement and time travel. Databricks provides collaborative notebooks, MLflow for ML lifecycle management and advanced streaming capabilities. These features make it attractive for complex machine learning pipelines and interactive analytics.
Pros and Cons
- Dataproc Advantages: fully managed, rapid cluster provisioning, integration with Google’s data ecosystem, decoupled storage via GCS, support for preemptible workers and customization through initialization actions. It’s ideal for organizations already invested in GCP and for migrating existing Hadoop/Spark workloads.
- Dataproc Limitations: autoscaling cannot scale clusters to zero and doesn’t support streaming, requiring manual adjustments for long‑running applications. Serverless Spark may introduce cold start delays and limits deep customization.
- Databricks Advantages: optimized Spark runtime, Delta Lake for ACID‑compliant lakehouse design, collaborative workspace with notebooks and MLflow and robust streaming performance. It’s cloud‑agnostic and offers advanced enterprise features like fine‑grained role management and unified data governance.
- Databricks Limitations: pricing based on DBUs can be harder to estimate, and the platform may be overkill for simple batch ETL workloads. It also requires adoption of the Databricks environment and tools.
Best Practices and Use Cases
When Dataproc Shines
- Migrating on‑premise Hadoop clusters: Organizations can lift and shift their existing MapReduce or Spark workloads to Dataproc with minimal code changes. Dataproc is a natural choice when migrating on‑premises Hadoop workloads or building hybrid cloud architectures.
- Data lake modernization: Dataproc’s decoupled storage model (compute separate from GCS) makes it well suited for modern data lake patterns and integration with BigQuery for analytics.
- Interactive data science and machine learning: The integration with Jupyter notebooks, Vertex AI and GPU accelerators (via serverless or cluster modes) supports data scientists who need ad‑hoc compute with minimal overhead.
- Cost‑sensitive batch processing: Because clusters can be created quickly and priced per second, Dataproc is cost‑effective for intermittent batch jobs. Preemptible workers and autoscaling allow teams to optimize resource usage.
When to Consider Dataflow or Databricks
- Choose Dataflow for complex streaming pipelines, event‑driven ETL and when using the Apache Beam programming model.
- Choose Databricks for advanced data lakehouse architectures requiring ACID transactions, integrated machine learning workflows and collaborative notebooks. Databricks also shines in cross‑cloud deployments or when vendor neutrality is important.
Conclusion
Google Cloud Dataproc has matured into a versatile and cost‑effective platform for running Spark, Hadoop and other open‑source frameworks in the cloud. Its architecture decouples compute from storage, enabling the creation of ephemeral clusters and integration with Google’s broader data ecosystem. Autoscaling and Serverless options further reduce operational overhead, though streaming support and zero‑scaling remain areas for improvement. Comparing Dataproc vs Dataflow reveals clear boundaries: Dataproc for customizable Spark/Hadoop jobs and Dataflow for Beam‑based streaming pipelines. Meanwhile, Dataproc vs Databricks highlights trade‑offs between managed open‑source flexibility and an optimized, lakehouse‑centric platform.
Ultimately, the right choice depends on your organization’s workloads, skillsets and cloud strategy. For teams invested in the Google Cloud ecosystem who need control over Spark and Hadoop jobs with minimal infrastructure management, Dataproc remains a compelling option. As the cloud analytics landscape evolves, staying attuned to advances in serverless, autoscaling and pricing models will ensure you continue to extract maximum value from your data platforms.


