What Is Dataplex? A Google Cloud Dataplex Overview
.png)
Introduction
If you’ve been hearing “Dataplex” and “Universal Catalog” in the same breath, you’re not imagining it. In 2025, Google Dataplex refers to Dataplex Universal Catalog—Google Cloud’s unified, intelligent governance layer for data and AI assets across BigQuery, Cloud Storage, and more.
What is Dataplex?

At its core, Google Dataplex is a governance and metadata fabric. It discovers and catalogs data, profiles and validates quality, tracks lineage, and gives your teams one place to search and apply consistent policy—all without copying your data. Think of it as your organization’s source of truth for data context that sits across Google Cloud.
A quick google cloud dataplex overview:
- Discovery & cataloging across BigQuery, Cloud SQL, Spanner, Vertex AI, Pub/Sub, and more, with the ability to ingest custom/third-party sources.
- Data insights, profiling, and quality to understand distributions, nulls, drift, and enforce rules.
- Business glossary to align language across the org.
- Data lineage to see where data came from, how it moved, and what transformed it.
- These are surfaced centrally in Dataplex, and many are also accessible from BigQuery.
Core Concepts: Lakes, Zones, and Assets
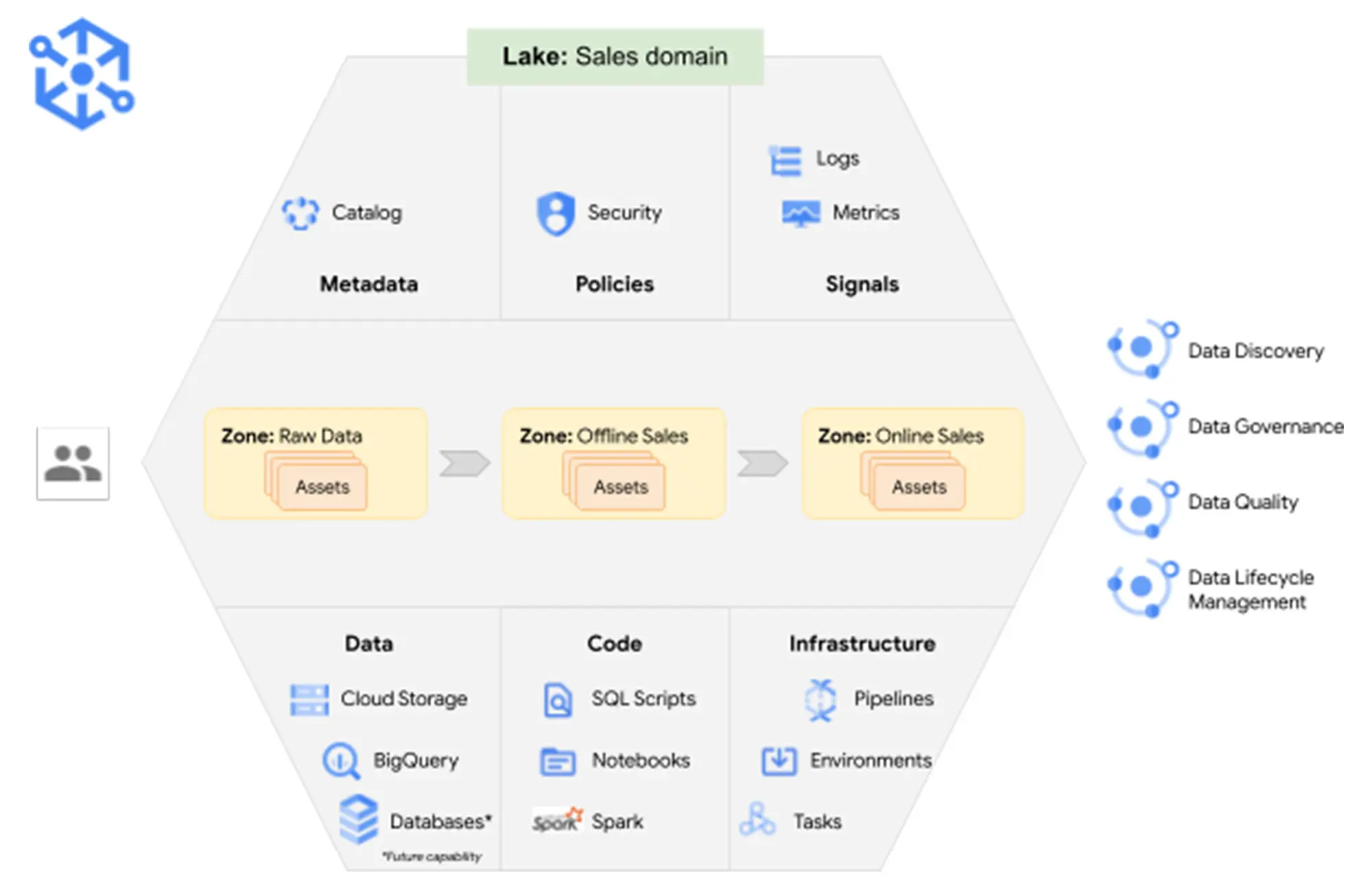
Dataplex organizes your data estate into lakes (logical groupings), zones (curated areas inside a lake), and assets (actual Cloud Storage buckets or BigQuery datasets). You attach assets from one or many projects into zones, giving you a single, governed view.
One powerful detail: when you “upgrade to Managed” for a Cloud Storage asset, Dataplex replaces external tables with BigLake tables—unlocking fine-grained security such as row/column policies and dynamic masking. You can also downgrade back to external tables if needed.
How Teams Actually Use Dataplex
1) Search & Metadata Management
Dataplex maintains a unified inventory and a richer metamodel than legacy Data Catalog: entries, aspects, aspect types, entry groups, and entry types that let you define required metadata and enforce standards. There’s also a documented transition path from Data Catalog.
2) Data profiling
Profiling identifies typical values, distributions, and null counts so you can classify data and set realistic rules. Profiling runs are billed as “processing” jobs (more on dataplex cost below).
3) Auto data quality (AutoDQ)
Define quality checks (row or aggregate), schedule scans, and log alerts when rules fail—managed as code if you prefer IaC. AutoDQ runs in place on BigQuery resources; no data copy is involved.
4) Business glossary
A business glossary gives shared definitions and lets you link terms to table columns to drive consistent usage. As of June 2025, glossaries in Dataplex Universal Catalog are GA, with migration guidance from older Data Catalog taxonomies.
5) Lineage
Dataplex data lineage shows how data flows—from sources to transformations to outputs. There’s a quickstart to track lineage for BigQuery copy/query jobs, and broader guides for viewing/considerations.
Governance And Security
Access is controlled with IAM roles (predefined or custom). Typical roles include viewer/editor/admin at lake or catalog scope, alongside service-agent permissions for Dataplex to attach and manage assets across projects. You’ll often grant the Dataplex service account (service-<PROJECT_NUMBER>@gcp-sa-dataplex.iam.gserviceaccount.com) the right roles on the underlying buckets/datasets.
Dataplex also works within VPC Service Controls; ensure your lake and assets align with your perimeter policies.
Integrations That Matter
- BigLake & BigQuery — Upgrading Cloud Storage assets to BigLake tables centralizes fine-grained access control, with policy enforcement consistent across engines. BigQuery queries naturally honor those controls, and open-source engines can integrate via Storage API connectors.
- BigQuery governance — Many governance features are exposed right inside BigQuery, powered by the Dataplex foundation. This tight coupling simplifies adoption for analytics teams.
- Pipelines and managed jobs — Some Dataplex features (scheduled quality scans, managed metadata ingestion) run on Dataproc Serverless, Dataflow, BigQuery, and Cloud Scheduler; those executions are billed under those services—not Dataplex. This separation helps when attributing costs.
Dataplex Pricing
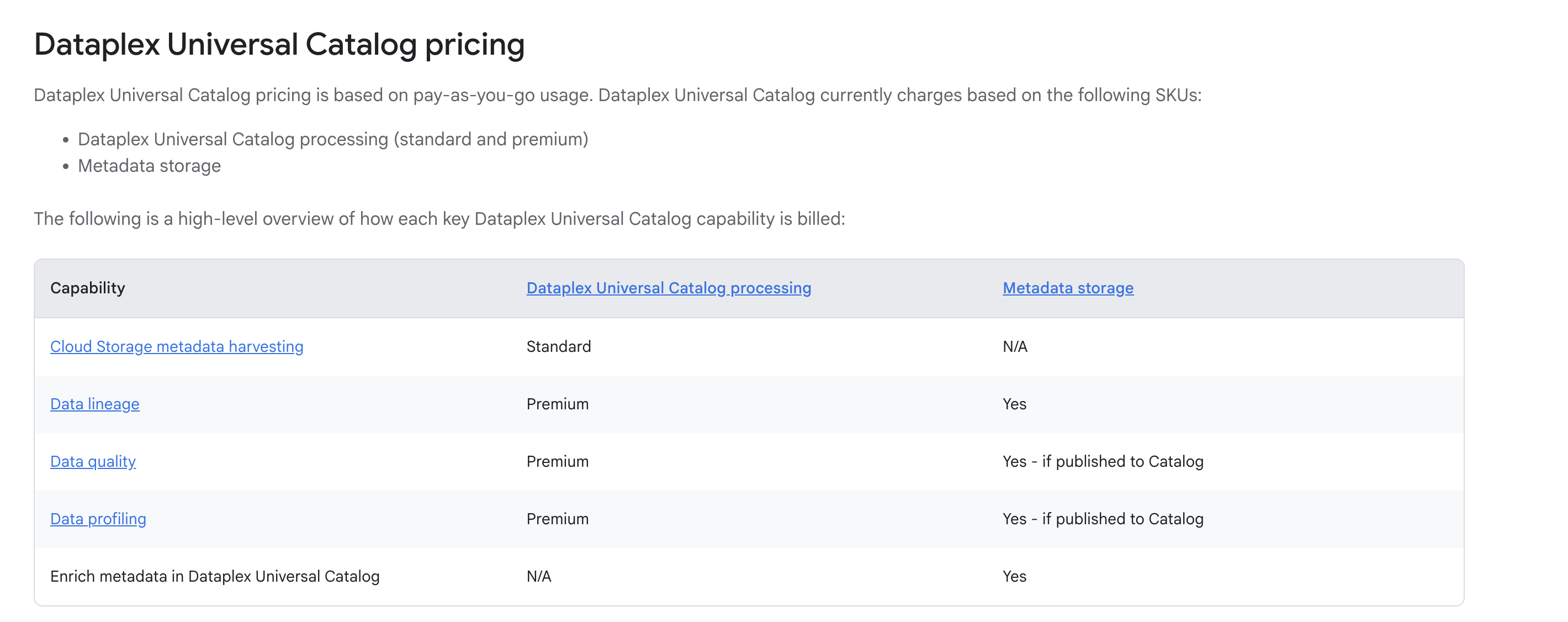
Image Source: cloud.google.com
This is the part everyone searches for—dataplex pricing and dataplex cost in real terms. Pricing has two primary components: processing (metered in DCU-hours) and metadata storage.
Processing (DCU-hours)
- Standard tier covers discovery; Premium tier covers data profiling and data quality. Charges are per-second with a 1-minute minimum, and rates are region-specific. For example, in us-central1:
- Standard: $0.060000 per DCU-hour
- Premium: $0.089000 per DCU-hour
- There’s also a 100 DCU-hour/month free allowance for standard processing. (Always check the live price table for your region.)
Metadata storage
- Catalog metadata storage is billed at $0.002739726 per GiB-hour, which is roughly $2 per GiB-month. This is for the catalog’s metadata footprint—not your underlying data.
Cost Controls You’ll Actually Use
Google’s pricing docs call out pragmatic levers:
- Sampling and incremental scopes for AutoDQ and profiling;
- Column/row filtering to reduce scanned data;
- Billing labels to isolate AutoDQ vs profiling on the Cloud Billing report (e.g., goog-dataplex-workload-type=DATA_QUALITY or DATA_PROFILE).
A Note On “Hidden Costs”
As mentioned above, if you schedule jobs that run on Dataproc/Dataflow/BigQuery, those costs land on the respective service—not on Dataplex. That’s by design; plan chargeback/showback accordingly.
When To Use Google Dataplex
Use GCP Dataplex when you need:
- Cross-project governance with a unified catalog, discoverability, and policy enforcement.
- Quality and lineage at scale, close to where data lives and is queried (especially in BigQuery).
- A data mesh-friendly foundation—lakes and zones map neatly to domain boundaries while keeping central governance.
- Business language alignment via a business glossary that your analysts and engineers can both live with.
It’s not a warehouse, and it’s not a substitute for pipeline engines. Pair it with BigQuery (for analytics), Dataflow/Dataproc (for processing), and BigLake (for table-level governance on Cloud Storage).
Getting Started
- Create a lake (pick the right project & region), then add zones that represent your domains or trust tiers.
- Attach assets (buckets/datasets). If you want fine-grained controls, upgrade Cloud Storage assets to Managed to create BigLake tables.
- Set IAM at lake/zone scope and authorize the Dataplex service account across projects as needed.
- Enable discovery, then profile a few key tables to baseline distributions and nulls.
- Add AutoDQ rules for the critical tables; start with sampling and incremental runs to keep costs in check. Wire alerts to your incident channel.
- Publish (or migrate) your business glossary and link terms to columns in the most-used datasets.
- Turn on lineage for key pipelines—start with BigQuery query/copy workflows; expand to other systems as supported.
Architecture Notes & Pitfalls
- VPC-SC & regions: keep lake region, metastore, and asset regions aligned with your VPC-SC perimeter; Dataplex enforces regional rules for attaching assets.
- Service accounts: you’ll often need to grant roles/dataplex.serviceAgent (and for BigQuery datasets, BigQuery Admin on the dataset) to the lake’s service account in other projects you attach.
- Gradual “Managed” adoption: upgrading to BigLake tables is excellent for governance, but do it incrementally to validate policy impact and performance.
- Metadata hygiene: Dataplex’s newer entries/aspects/entry types model is flexible—use entry types to enforce minimum metadata so your catalog remains trustworthy.
- Cost guardrails: standardize AutoDQ sampling, set maximum scan durations, and label your jobs so Finance can slice costs cleanly.
The Bottom Line
If your organization keeps adding datasets, projects, and pipelines, Dataplex gives you the control plane to keep that growth safe and navigable—without pulling data into another silo. Start small (one domain, a handful of assets), wire up profiling and a few high-value quality checks, and let the glossary and lineage catch up with adoption. You’ll get to “governed, findable, trustworthy data” faster—and with clearer costs—than trying to stitch it yourself.


