AI Cost Allocation: How to Know Which Team, Feature, or Workflow Is Actually Spending

Introduction
Most organizations can now see that they're spending on AI. The monthly invoice from OpenAI or Anthropic shows up. The line item on the cloud bill is there. Leadership asks about it in quarterly reviews.
What they still can't answer is who is spending it, on what, and whether it's working.
Only 43% of organizations track cloud costs at the unit level, meaning most enterprises cannot translate what they spend into business language like cost per product, cost per feature, or cost per customer. That was already a problem for cloud infrastructure. For AI, it's worse. The cost structure is different, the tooling hasn't caught up, and the usage is embedded inside applications in ways that make traditional tagging approaches fall short.
Without allocation, you can't enforce accountability. You can't build a meaningful chargeback. You can't make intelligent prioritization decisions when budgets get squeezed. The organizations that are genuinely winning at AI cost management aren't just tracking spend, they're attributing it.
You cannot optimize what you have not attributed. Allocation isn't the end goal. It's the foundation everything else is built on.
Why AI allocation is harder than cloud allocation
AI isn't just more cloud. It's a fundamentally different cost structure that breaks most existing allocation approaches. Teams trying to drop AI billing into their existing FinOps frameworks quickly run into three specific walls.
Token-based billing is foreign to FinOps tooling
Cloud services bill by compute hours, storage capacity, or data transfer. AI models charge primarily based on token consumption, and AI API calls often provide limited or no native tagging capabilities. Your existing tagging infrastructure doesn't reach into inference calls. The abstraction layer that makes AI easy to use also makes it opaque to the cost systems sitting above it.
Shared models create attribution ambiguity
Provisioned Throughput Units (PTUs) and reserved capacity are common cost-saving strategies for high-volume AI workloads. The problem: it's standard for multiple teams or use cases to share a single PTU deployment. Splitting a flat monthly commitment across five product teams requires an entirely different methodology than tagging EC2 instances. The infrastructure is shared; the attribution logic has to be built manually.
AI usage is embedded in features, not infrastructure
Cloud resources map to accounts, projects, and tags. AI usage is embedded inside product features, internal workflows, and agent chains; it crosses teams and systems by design. A single customer support ticket might touch a classification model, a retrieval system, a summarization call, and a response generation step. Attribution requires following that chain, not just reading a billing dashboard.
This isn't a tooling gap you can paper over with better dashboards. It requires a different mental model for how allocation works.
Showback vs. chargeback: which model fits where
Most teams starting with AI allocation should begin with showback and earn their way to chargeback. The distinction matters because each model produces different organizational behavior.
Showback
Teams see their AI costs without being billed for them. This builds awareness and opens conversations without creating friction or resistance. It's the right starting point for most organizations, particularly when engineering teams are still instrumenting their applications and the attribution data is incomplete or imprecise.
Chargeback
Teams are directly billed for their consumption. This model ensures that the teams with authority to make spending decisions also bear the financial consequences of those decisions. That alignment produces better behavior: teams are more likely to optimize prompts, implement caching, and question whether a particular AI feature is actually worth its cost.
Chargeback is more powerful, but it requires cleaner attribution data and organizational trust to implement without creating internal conflict. Charging teams before they have visibility is a cultural mistake; you create resentment without creating understanding.
Pro tip: When to move from showback to chargeback: when teams have had 60–90 days to see their numbers, understand what's driving them, and have agency to change behavior.
The four layers of AI cost attribution
AI cost attribution can happen at four levels of granularity, from broad to precise. Most organizations need to climb this stack deliberately; each layer builds on the one below it.
Layer 1: Provider billing (table stakes)
Pull raw spend data from OpenAI, Anthropic, AWS Bedrock, Azure OpenAI, and Vertex AI invoices. This tells you the total spend by provider and by model. It's necessary but not sufficient. You know you spent $47,000 on GPT-4o last month. You still don't know which team spent it, on which product, for what purpose.
Layer 2: Account and project segregation
Use separate API keys or cloud sub-accounts per team or product line. This is the bluntest instrument, but it works without requiring application-level changes. Engineering teams can route requests through designated keys per use case. Some organizations never need to go further than this, particularly early-stage teams or those with clear product line boundaries. Most will need to go deeper.
Layer 3: Request-level tagging
Pass metadata with every inference call: team identifier, feature name, user segment, workflow type. This is where real allocation lives. It requires engineering effort - instrumentation at the application layer, but it unlocks per-feature and per-workflow cost breakdowns that make AI cost optimization possible.
Most LLM observability platforms support this metadata. The gap isn't capability, it's enforcement. Teams need a standard and a mechanism (an API gateway wrapper, an SDK shim) that makes tagging automatic rather than optional.
Layer 4: Business-outcome attribution
Map AI costs to the business value being generated: cost per completed workflow, cost per conversion, cost per resolved ticket. Cost per token is an infrastructure metric. Cost per outcome is an economic metric. Most organizations are still guessing in the space between those two numbers. This is the hardest layer to instrument and the most valuable for conversations with leadership about whether the AI investment is actually paying off.
Pro tip: Practical guidance: get to Layer 3 before worrying about Layer 4. If you can't see cost by feature, you can't optimize by feature.
What good tagging looks like for AI workloads
Tagging for AI workloads is different from tagging cloud infrastructure. The tags don't live on resources; they live on requests. Here's a minimal but effective tagging taxonomy to start with:
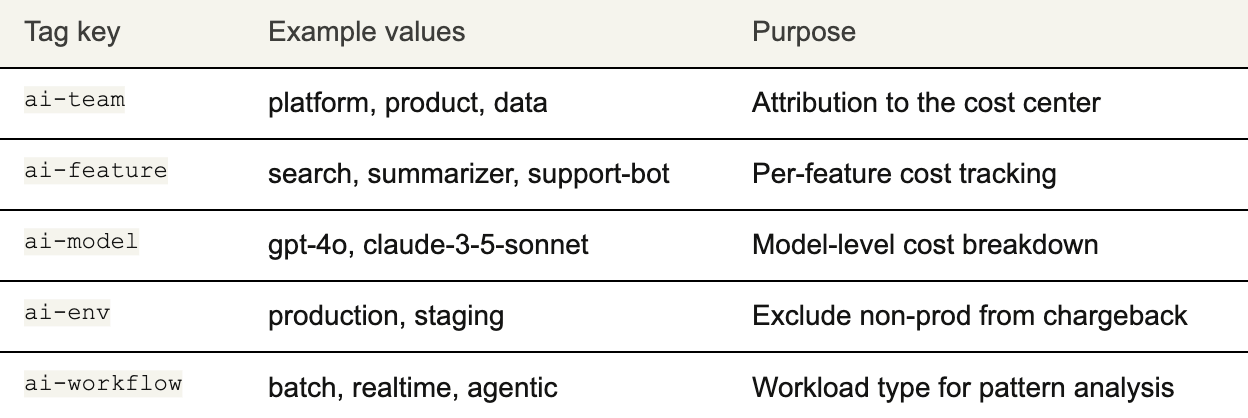
A few principles that determine whether this taxonomy actually works in practice:
- Tags must be passed at the request level, not just the infrastructure level. A tag on an EC2 instance tells you nothing about which model call came from which feature.
- Enforce tagging at the API gateway or SDK wrapper. Don't rely on individual engineers to remember. The same way cloud teams use policy guardrails to enforce resource tagging, AI teams need enforcement at the call layer.
- Untagged spend is the enemy of allocation. Track the percentage of spend that's unattributed and treat it like technical debt. Teams need to apply the same maturity path they used for cloud: first gain visibility, then build planning discipline, then optimize for value.
Shared AI cost pools: the hardest allocation problem
The most common scenario teams struggle with is shared AI infrastructure, e.g. a shared model deployment, a shared RAG pipeline, a shared vector database that multiple teams draw on simultaneously. The infrastructure cost is singular; the attribution problem is complex.
Proportional split
Divide the shared cost by usage volume: token counts, request counts, or wall-clock time. This is simple and defensible. It's also slightly unfair to heavier users in ways that are hard to dispute. Good starting point for teams that don't yet have timestamp-level instrumentation.
Utilization-weighted split
Combine PTU utilization data with discrete timestamps. If between 9am and 10am your PTU was at 30% utilization, collect token usage during that window, calculate the effective rate, and assign the cost to the use cases active during that time. More accurate, but requires better instrumentation and more sophisticated billing logic. This is where most mature FinOps programs for AI land.
Ring-fencing
Give each team its own inference quota and bill against that. This produces the cleanest allocation, but requires pre-committed capacity planning and enough volume to justify dedicated provisioning. Not practical for smaller use cases, but the right answer for large, stable production workloads.
The right approach depends on how mature your instrumentation is and how much internal friction your organization can absorb. Start simple and evolve.
Getting the organization ready
Allocation is as much a people problem as a technical one. The tooling is available. The methodology exists. The gap is almost always organizational. Three prerequisites determine whether an allocation program sticks.
Engineering must own the instrumentation
FinOps teams can define the taxonomy and the standards. But engineers have to implement the tagging at the application layer. This requires a shared language between FinOps and engineering, and that gap is real: 52% of engineering leaders say the disconnect between FinOps and developers is leading to wasted spend.
Frame request-level tagging as an engineering standard, not a finance ask. Position it alongside other observability requirements, the same way you'd require logging or tracing, you require cost tagging. It belongs in the engineering contract for every AI feature shipped.
Finance needs to understand AI-specific behavior
Cost spikes from a model version upgrade, a new feature launch, or a scheduled batch job aren't mismanagement; they're expected behavior. Finance teams that treat every spike as a problem create a chilling effect on experimentation. The goal is understanding the cost signature of different workloads, not reflexive alarm at variance.
Start with the teams spending the most
Don't try to allocate everything at once. Identify the two or three teams or product lines responsible for the majority of AI spend and build the attribution model there first. Get it right in a bounded context, prove the value, then expand from proven foundations rather than from a blank governance policy.
Allocation programs that try to boil the ocean on day one stall. Programs that start narrow, build trust, and expand incrementally are the ones that actually reach chargeback.
Putting it into practice with Cloudchipr
The framework above answers the methodology question. The harder problem for most teams is the operational one: you need a platform that consolidates AI and cloud spend in a single view, surfaces attribution gaps automatically, and doesn't require a bespoke analytics stack to generate the reports that FinOps and engineering actually use.
This is where Cloudchipr fits into the allocation workflow. Rather than requiring teams to stitch together provider billing exports, custom dashboards, and manual tagging audits, Cloudchipr provides granular cost attribution across your full infrastructure, cloud and AI workloads together, with anomaly detection that explains spend changes in plain language rather than leaving teams to dig through raw data.
For AI specifically, that means being able to answer questions like "why did our AI spend spike 40% this week?" without scheduling an investigation. Cloudchipr's AI agents surface the answer automatically, whether it's a new feature rollout, a model version change, or an agentic workflow that ran longer than expected, and deliver it to the stakeholders who need it, in the format they can act on.
The visibility foundation that allocation depends on is the following: consolidated multi-provider spend, consistent tagging enforcement, and showback reporting by team and feature. This is what Cloudchipr is built to provide. Teams that get attribution right tend to optimize faster, forecast more accurately, and have more productive conversations between engineering and finance. The platform is designed to make that progression easier at every stage, from the first showback report to a mature chargeback model.
If you're working through AI cost allocation and want to see how Cloudchipr handles it in practice, the best starting point is a short product walkthrough with your actual data. Request a Personalized Demo →
Allocation is the foundation, not the goal
The purpose of AI cost allocation isn't to assign blame or create friction between teams. It's to give teams the information they need to make better decisions about what they build and how they build it.
Allocation, forecasting, budgeting, and planning are consistently the top-prioritized capabilities as FinOps extends into AI. Organizations focus first on understanding and structuring costs before they can reduce them. This sequencing isn't a phase to rush through; it's what makes everything downstream possible.
When a product manager can see the fully-loaded cost of the AI feature they shipped last quarter, they can make a real decision about whether to optimize it, expand it, or retire it. When an engineering team can see cost-per-workflow instead of cost-per-token, they can have a business conversation instead of an infrastructure one. When finance can see which teams are managing their AI budget responsibly, they can reward that behavior instead of applying blanket pressure.
That's what attribution makes possible. You can't optimize what you haven't attributed. Build the foundation first.


