AI vs Cloud Cost Visibility: Why AI Spend Is Structurally Harder to Observe

The visibility problem most teams don't see coming
For most engineering and finance teams, getting visibility into cloud costs felt like a solved problem. After years of investment in tagging policies, cost allocation tools, and FinOps practices, the average organization could tell you how much AWS EC2 was costing in production, which team owned it, and whether it was trending up or down.
Then AI entered the stack. And quietly, almost overnight, that hard-won visibility started to erode.
The erosion isn't obvious at first. AI costs still show up somewhere on a bill. They're not invisible. But they're structurally different in ways that make traditional visibility frameworks insufficient. Not because the tools are bad, but because the cost model itself has changed in fundamental ways.
This article breaks down exactly what those differences are, why they matter, and what organizations need to do to restore observability across a stack that now spans both cloud infrastructure and AI services.
Why this matters now
According to the FinOps Foundation's 2026 survey, AI workload costs have become a top-five spend category for over 60% of organizations, yet fewer than 30% report having adequate visibility into AI spend at the team or product level. The gap is growing faster than most organizations realize.
How cloud cost visibility actually works
To understand why AI cost visibility is harder, it helps to appreciate how cloud cost visibility became manageable in the first place.
Cloud providers, such as AWS, Azure, and Google Cloud, emit structured billing data with consistent granularity. Every resource has a resource ID, a service type, a region, and a timestamp. Costs are denominated in consistent units: instance-hours, GB-months, request counts. They can be tagged at the resource level and filtered across any dimension you define.
Over time, FinOps teams built playbooks around this structure: tag everything, allocate by team or product, set budgets per environment, alert on anomalies. Tools like cloud cost management platforms made it possible to consolidate multi-cloud billing into a single view, identify idle resources, and automate cleanup workflows. The result was a mature practice with clear metrics, clear owners, and clear levers.
It wasn't perfect, tag hygiene is still a recurring headache for most teams, but the architecture of observability was well-established. Costs were attached to infrastructure. Infrastructure was owned by teams. Teams had tooling to see and act on their spend.
That architecture assumed something that AI quietly invalidates: that the unit of cost is a resource, and that resources can be tagged.
Why AI cost visibility is a different beast
AI costs, whether from LLM APIs, GPU compute, managed AI services, or embedded AI features, don't fit the resource-tagging model. They're driven by consumption patterns that are dynamic, ephemeral, and often shared across multiple teams and use cases simultaneously.
Consider a simple example: your company uses OpenAI's GPT-4o API for three features: a customer support bot, an internal knowledge assistant, and a document summarization tool. All three features call the same API endpoint. The bill arrives as a single line item: "OpenAI API: $47,283." You know the total. You don't know the breakdown. You don't know which feature is responsible for the cost spike in the second week of the month. You don't know which team's prompt engineering decisions are driving inefficiency.
This is the essence of the AI cost visibility problem. It's not that the data doesn't exist; token counts and request logs are available. It's that the systems to collect, attribute, and act on that data are typically absent, immature, or built bespoke by individual teams.
As explored in Cloudchipr's guide on FinOps for AI, the traditional cloud cost playbook breaks down precisely because AI introduced a new cost model that FinOps practices weren't designed for.
The five structural gaps between cloud and AI spend observability
Let's be specific. Here are the five structural differences that make AI spend harder to observe than cloud infrastructure spend:
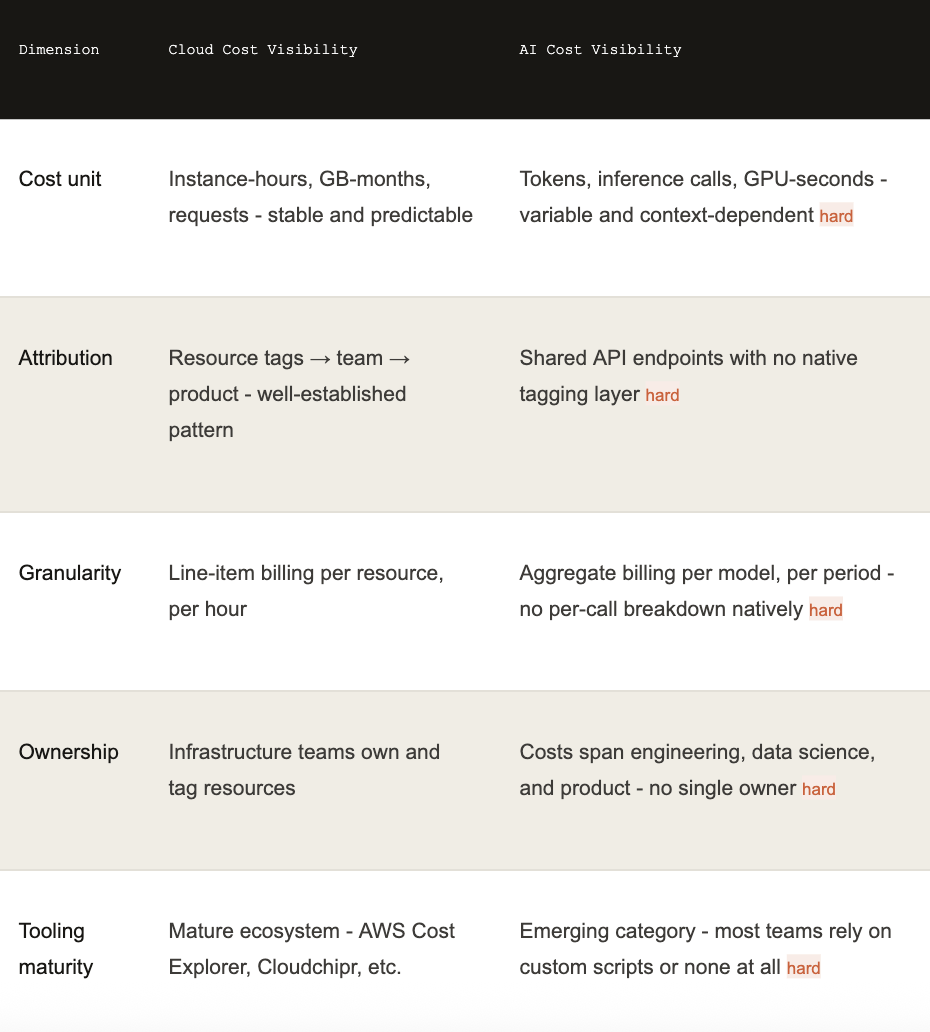
Gap 1: The unit of cost is not a resource
Cloud billing attaches cost to resources - identifiable, persistent objects with IDs, regions, and lifecycle states. A terminated EC2 instance stops generating cost. An idle RDS database can be rightsized or shut down. The unit of optimization is clear.
AI billing attaches cost to consumption events - individual API calls, token exchanges, inference requests. These events are ephemeral, high-frequency, and don't map to any named resource in your infrastructure inventory. You can't "rightsize" a token. You can't "terminate" an LLM request that already happened. Optimization requires working upstream, at the prompt, model selection, and architecture level.
This changes the entire observability posture. You're no longer monitoring a fleet of resources. You're monitoring a pattern of behavior that generates cost dynamically, often at rates that can spike by 10x within a single hour if something changes in how a feature is used.
Gap 2: Attribution requires instrumentation you probably don't have
Attributing cloud costs to teams is a tagging problem which is annoying, but solvable. Most organizations have reached 80–90% tag coverage on their cloud infrastructure. The remaining gap is typically addressed through cost allocation rules and tools like Cloudchipr's Dimensions feature, which creates dynamic attribution rules without requiring retroactive re-tagging.
Attributing AI costs to teams requires a fundamentally different approach. API calls to OpenAI, Anthropic, or Google Vertex don't carry team metadata unless you instrument your application code to inject it. That means your backend services need to pass custom headers or logging metadata on every API call, your telemetry pipeline needs to capture and route that data, and your cost analysis tooling needs to aggregate it at the team or feature level.
Most engineering teams haven't built this. It's not on the standard observability checklist. The result is that AI costs remain pooled at the service level, unattributed to the features or teams that generated them.
This is one of the core challenges addressed in Cloudchipr's deep dive on AI cost allocation and chargeback - the mechanics of splitting AI spend across teams and products when native billing doesn't provide that granularity.
Gap 3: Cost behavior is non-linear and hard to forecast
Cloud costs are broadly predictable. If you add 10 more EC2 instances, you know roughly what they'll cost per month. Reserved Instance and Savings Plan commitments further smooth out variability. Even traffic spikes in cloud infrastructure tend to scale costs proportionally.
AI costs can be wildly non-linear. A single change in a system prompt, such as adding a few hundred tokens of context, can increase per-call cost by 20–30%, multiplied across millions of daily calls. A new agentic workflow that chains multiple model calls can suddenly spike inference costs by orders of magnitude compared to a single-call baseline. A change in user behavior (longer queries, more conversational turns) can double LLM spend without any infrastructure change.
This non-linearity makes anomaly detection both more critical and harder to calibrate. What looks like a cost spike might be a legitimate increase in user engagement. What looks like normal growth might be a prompt regression that someone will notice only at the end of the billing cycle.
The risks of ungoverned agentic workloads are covered in detail in Cloudchipr's guide to managing costs in the age of AI agents - a recommended read for any team deploying autonomous workflows.
Gap 4: Ownership is structurally ambiguous
In cloud infrastructure, cost ownership is relatively well-defined. The team that deploys the resource owns its cost. FinOps establishes allocation rules, finance tracks budgets by team, and engineers have dashboards that show their slice of the bill.
AI cost ownership is genuinely ambiguous. The data science team selects the model. The engineering team builds the integration. The product team defines the use case. The platform team manages the API keys and quota. Finance is asked to explain the bill. All four groups contributed to the cost. None of them has a single pane of glass showing their share of it.
This ambiguity isn't just a tooling problem; it's a process and accountability problem. Without a clear owner for AI costs at the feature or product level, no one has the mandate or the incentive to optimize them. Costs drift upward by default.
Gap 5: The tooling ecosystem is immature
Cloud cost management has a rich ecosystem of tools: from native options like AWS Cost Explorer to sophisticated third-party platforms. This ecosystem took roughly a decade to mature. Organizations adopting cloud in 2015 had limited visibility; organizations adopting cloud in 2025 have mature practices and proven tooling to draw from.
AI cost observability is at roughly the 2013 stage of cloud cost management: the equivalent of before tagging standards, before FinOps as a discipline, before centralized multi-cloud billing views. Most teams are either relying on provider-native billing dashboards (which lack attribution and granularity) or building bespoke internal tooling that doesn't scale.
The opportunity
The organizations that invest in AI cost visibility infrastructure now, before AI spend becomes a top-five budget line, will have a structural advantage over those that treat it as a future problem. The playbook for cloud cost visibility took a decade to develop. AI FinOps teams that adopt structured observability early will compress that timeline significantly.
What good AI cost visibility looks like in practice
Building genuine AI cost visibility requires addressing each of the five gaps described above. Here's what a mature AI cost observability stack looks like:
1. Token-level telemetry with request metadata
Every API call to an LLM provider should log at minimum: the calling service, the feature or use case identifier, the model used, input token count, output token count, and timestamp. This data feeds your cost attribution layer and enables per-feature cost analysis that no billing dashboard will give you natively.
Pair this with the benchmarks in Cloudchipr's token cost benchmark guide to understand whether your per-token costs are competitive across GPT, Claude, Gemini, and open-source alternatives.
2. Dynamic cost attribution rules
Static tag-based attribution doesn't work for AI costs, because there are no resources to tag. What you need instead are dynamic attribution rules; logic that maps API call metadata to teams, products, and cost centers based on rules you define.
This might look like: "All API calls from the customer-support-service with use-case tag ticket-resolution are allocated to the Customer Success team's AI budget." These rules need to be maintained and updated as your AI stack evolves.
3. Real-time cost monitoring with intelligent alerts
Because AI costs can spike non-linearly and quickly, real-time alerting is essential: not end-of-day batch alerts, and not static threshold alerts that you set once and forget. You need anomaly detection that understands the baseline pattern for each use case and alerts on meaningful deviations, with enough context to make the alert actionable.
An alert that says "AI API spend is up 40% today" is not actionable. An alert that says "Customer support bot cost is up 40% today, driven by a 3x increase in average conversation length in the EU region, starting at 14:00 UTC" is.
4. Unified visibility across cloud and AI spend
The worst-case scenario is a fragmented visibility landscape where cloud costs live in one dashboard, LLM API costs live in another, and GPU compute lives in a third. This fragmentation makes it impossible to reason about total infrastructure cost per product, impossible to detect cross-domain anomalies, and impossible to make informed trade-off decisions (e.g., managed API vs. self-hosted inference).
Best-in-class AI cost visibility is unified with cloud cost visibility: a single pane showing AWS, Azure, GCP, and AI service costs, attributed consistently to the same teams and products.
5. Actionable recommendations, not just reporting
Visibility without action is just reporting. The goal of an AI cost observability stack is not to produce dashboards that finance reviews monthly. It's to surface specific, actionable recommendations that engineering teams can act on immediately: switch this use case to a cheaper model tier, add prompt caching for this high-frequency query pattern, set a token budget cap for this workflow that's running without guardrails.

How Cloudchipr bridges the gap
Cloudchipr was built as the answer to exactly this kind of multi-layer cost visibility challenge. It started as a cloud cost management platform: one of the first to provide genuinely unified multi-cloud visibility across AWS, Azure, and GCP in a single pane, and has evolved into a platform that speaks the language of both infrastructure cost and AI spend.
The result is a platform that addresses the core gaps in AI cost visibility: attribution without complete tagging, anomaly detection calibrated to non-linear cost behavior, and unified visibility across cloud and AI spend in a single operational surface.
As explored in Cloudchipr's practical guide to AI cost optimization, the organizations seeing the strongest results are those that treat AI cost visibility as infrastructure, not a reporting afterthought.
What to do right now
If your organization is in the early stages of building AI cost visibility, here's a practical starting sequence:
- Audit your current AI cost data: Where does AI spend actually show up today? Is it in a cloud provider bill (e.g., AWS Bedrock, Google Vertex)? In a third-party API bill (OpenAI, Anthropic)? In a separate GPU compute budget? Understanding the data landscape is step zero.
- Identify your top three unattributed cost pools: Most organizations have a handful of large AI spend lines that no one "owns." Name them explicitly. Assign interim owners. Start tracking them week over week.
- Instrument one high-cost AI feature with request-level metadata: Pick your most expensive AI feature and add use-case logging to every API call. This is a small engineering investment that unlocks attribution for that feature immediately.
- Set up a real-time alert on your largest AI spend line: Even a simple threshold alert is better than finding out about a 3x cost spike at month-end. Refine the alert logic over time as you build baseline data.
- Unify cloud and AI costs in a single view: If you're using separate tools for cloud and AI cost tracking, this is the single highest-leverage change you can make. Unified visibility enables cross-domain analysis, shared accountability, and coherent governance.
The gap between cloud cost visibility and AI cost visibility is real, but it's closeable. The organizations that close it earliest will be the ones with the clearest picture of their true infrastructure economics, and the most leverage over one of the fastest-growing cost categories in enterprise technology.


